
データベースにSQL Server2022を使用していて、使用しているうちに検索やデータ登録などの処理が遅くなることがあり、それはSQL Serverの問題かもしれません。
SQL Serverが遅い原因
SQL ServerのSQL操作が遅くなる場合、よくある原因はSQLクエリの書き方が良くなかったり、インデックスの設定が適切ではなかったりすることが多く、この場合はSQLを書き直したり、検索に使用されるカラムのインデクスを見直したりすることで改善されます。
これ以外にSQL Serverのサーバ運用担当者が確認・対処すべき点は次の通りです。
■SQL Serverのサーバ運用担当者が確認・対処すべき点
- インデックス断片化
- データファイルの断片化
- 統計情報が古い
- メモリ不足
- ディスクIO(ストレージ)性能不足
運用でできるSQL Serverのパフォーマンス改善
SQL Serverのサーバ運用担当者が日々の運用で対応すべきポイントを説明します。
インデックス断片化の解消
データベースのテーブルに設定したインデックス(索引)は、本来「順番どおり」に並んでいることで高速に検索できます。
しかし、INSERTやUPDATE、DELETEを繰り返すと、この順番が崩れて断片化が発生していきます。
インデックス断片化の確認方法
インデックスと断片化率の一覧を次のSQLで確認できます。
--行ストア インデックスの断片化とページ密度を確認する
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_fragmentation_in_percent,
ips.avg_page_space_used_in_percent,
ips.page_count,
ips.alloc_unit_type_desc
FROM sys.dm_db_index_physical_stats(DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND ips.index_id = i.index_id
ORDER BY page_count DESC;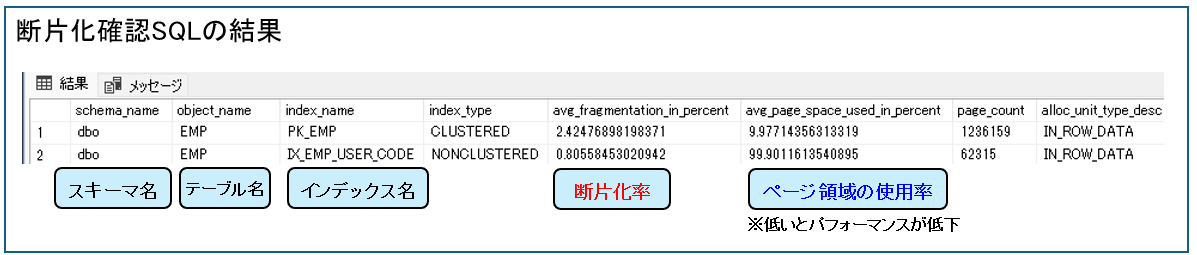
断片化解消(インデックス再編成・再構築)手順
一般的に断片化率によって次のように対応します。
- 5%未満 → 何もしないなくて良い
- 5〜30% → インデックスの再編成(REORGANIZE)
- 30%以上 → インデックスの再構築(REBUILD)
インデックス再編成(SQLによる実施)
再編成はシステム利用中でも実行できるので、定期的に実施するのが良いです。
次のSQLをタスクスケジューラーなどで実行すれば再編成ができます。
SET NOCOUNT ON;
DECLARE
@schema_name NVARCHAR(128),
@table_name NVARCHAR(128),
@index_name NVARCHAR(128),
@frag FLOAT,
@sql NVARCHAR(MAX);
DECLARE cur CURSOR FOR
SELECT
s.name AS schema_name,
o.name AS table_name,
i.name AS index_name,
ips.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED') ips
INNER JOIN sys.indexes i
ON ips.object_id = i.object_id AND ips.index_id = i.index_id
INNER JOIN sys.objects o
ON ips.object_id = o.object_id
INNER JOIN sys.schemas s
ON o.schema_id = s.schema_id
WHERE
o.type = 'U'
AND ips.page_count > 1000 -- 小さいページは無視
AND i.index_id > 0
AND ips.avg_fragmentation_in_percent >= 10; -- 無駄撃ち防止
OPEN cur;
FETCH NEXT FROM cur INTO @schema_name, @table_name, @index_name, @frag;
WHILE @@FETCH_STATUS = 0
BEGIN
-- 業務中はREORGANIZEのみ
SET @sql = N'ALTER INDEX [' + @index_name + '] ON ['
+ @schema_name + '].[' + @table_name + '] REORGANIZE';
BEGIN TRY
PRINT @sql;
EXEC sp_executesql @sql;
-- 負荷を分散
WAITFOR DELAY '00:00:01';
END TRY
BEGIN CATCH
PRINT 'ERROR: ' + ERROR_MESSAGE();
END CATCH;
FETCH NEXT FROM cur INTO @schema_name, @table_name, @index_name, @frag;
END
CLOSE cur;
DEALLOCATE cur;インデックス再構築(SQLによる実施)
インデックスの再構築は、テーブルをロックする方法と、しない方法(オンライン時間帯でも実施可能)があります。
ALTER INDEX [インデックス名] ON [テーブル名] REBUILD製品版であれば「WITH (ONLINE = ON)」を付けてオンライン中でもインデックス再構築ができます。
ALTER INDEX [インデックス名] ON [テーブル名] REBUILD WITH (ONLINE = ON)統計情報が古い場合は更新
大量データを追加・更新・削除をした場合、統計情報が古くなり、SQLが遅くなることがあります。
次のSQLでどのテーブルの統計情報がいつ更新されたかを確認できます。
SELECT
t.name AS table_name,
s.name AS stats_name,
sp.last_updated,
sp.rows,
sp.rows_sampled,
sp.modification_counter
FROM sys.stats s
JOIN sys.tables t
ON s.object_id = t.object_id
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) sp
WHERE sp.last_updated IS NOT NULL
ORDER BY sp.last_updated desc;現在のデータベースに対し、統計情報を一括で更新する場合は、以下の命令を実行します。
EXEC sp_updatestats;SQL Serverの統計情報に関する詳しい解説や手順は「SQL Server統計情報の役割、実行方法の解説」を参照してください。
縮小(圧縮)は必要最低限に
復旧モデルが完全の場合、INSERTやUPDATEなどの操作でログファイルやデータベース領域が膨らんでいきます。
これが膨らむとパディスク容量を圧迫し、ログファイルやデータベース領域の圧縮をすることがあります。
以下のように、日次や月次でのバックアップとセットで縮小をしているシステムが稀にありますが、頻繁に圧縮を実施することは、断片化の原因になります。
- バックアップ
BACKUP LOG [データベース名] TO DISK = ‘バックアップ先パス’; - ログファイル縮小
DBCC SHRINKFILE (ログファイル名, 1024);
縮小についての詳しい説明は「SQL Server 縮小(圧縮)の仕組みと注意点」を参照してください。
SQL Serverチューニングでパフォーマンス改善
メモリ容量見直し
メモリが足りない場合、SQL Serverのパフォーマンスは低下します。
先ずはメモリが足りているか状況を確認する必要がありますが、以下の4つの観点で定期的に監視をする必要があります。
- OS視点で搭載メモリが足りているか
- SQL Serverが理想とするメモリ(最適なメモリ)が確保できるか
- データがメモリに存在できる時間(Page Life Expectancy(PLE))は十分か
- メモリ待ちで止まっているクエリの数(Memory Grants Pending)は無いか
各々の詳細を説明します。また、最後には一括で取得するスクリプトも用意しています。
SQL Serverのメモリに関する説明は「SQL Serverのメモリ構成・役割・仕組み」を参照してください。
OS視点で搭載メモリが足りているか
OS視点で搭載メモリが足りているかの確認は、空きメモリを確認すれば良いです。
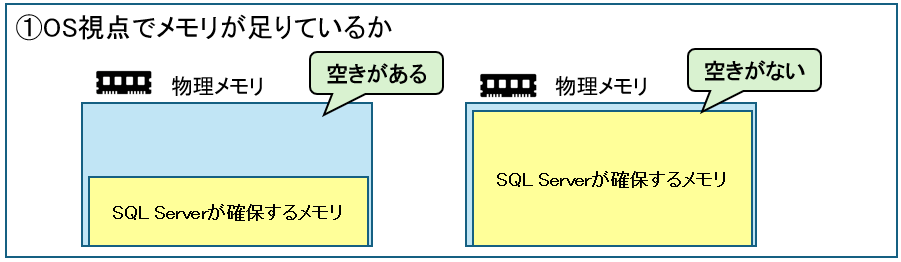
これはOSのタスクマネージャーでも確認できますが、SQLでも搭載しているメモリ、空きメモリを確認できます。
SELECT
total_physical_memory_kb AS 物理メモリ合計KB,
available_physical_memory_kb AS OSから見た空きメモリKB
FROM sys.dm_os_sys_memory;SQL Serverは意図的にメモリを確保し続けるため、空きメモリが少ないこと自体は必ずしも問題ではない。
SQL Serverが理想とするメモリ(最適なメモリ)が確保できるか
SQL Serverは、クエリ(SQL)の実行などに必要な「理想とするメモリ(最適なメモリ)」を算出しています。
これが現時点で「SQL Serverが確保しているメモリ」に収まるようであれば問題ありません。
通常、「確保しているメモリ」は、必要に応じて「理想とするメモリ」へ徐々に近づきます。
「確保しているメモリ」<「理想とするメモリ」が続くようであれば、この次にある「データがメモリに存在できる時間(Page Life Expectancy(PLE))は十分か」と、「メモリ待ちで止まっているクエリの数(Memory Grants Pending)は無いか」も確認しておく必要があります。
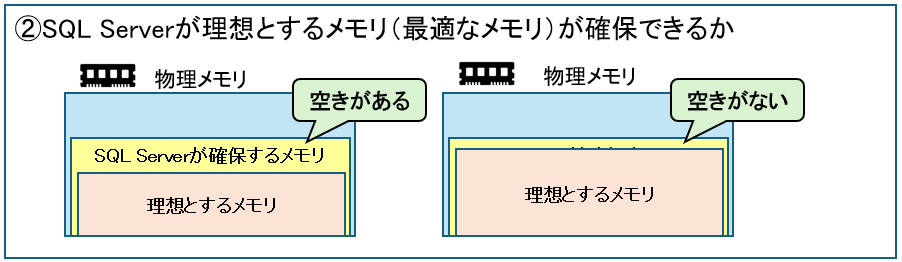
「理想とするメモリ(最適なメモリ)」、「SQL Serverが確保しているメモリ」は次のSQLで取得できます。
SELECT
opm1.cntr_value as 理想とするメモリKB,
opm2.cntr_value as 確保しているメモリKB
FROM
(SELECT counter_name, cntr_value FROM sys.dm_os_performance_counters WHERE counter_name ='Target Server Memory (KB)')opm1
,(SELECT counter_name, cntr_value FROM sys.dm_os_performance_counters WHERE counter_name ='Total Server Memory (KB)')opm2データがメモリに存在できる時間(Page Life Expectancy(PLE))は十分か
SQL Serverはデータをディスクではなくメモリにキャッシュします。
しかし、メモリが足りないと、キャッシュがすぐ追い出され、何度もディスク読み込み発生して、クエリなどの応答が遅くなります。
SQL Serverは、データがメモリにどれくらい長く居られるか(秒)を取得できます。
なお、この時間は300秒が目安と言われることもありますが、サーバーのメモリ容量に依存します。
・1000秒以上 → 良好
・継続的に低下 → メモリプレッシャーの可能性
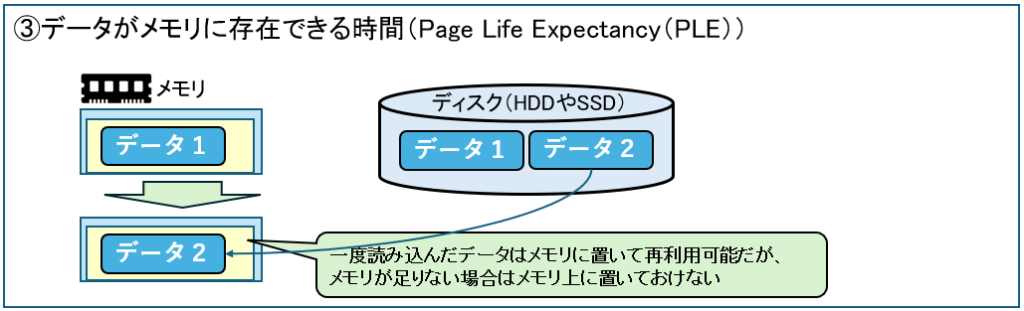
SELECT MAX(cntr_value) as データがメモリに存在できる時間秒
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Page life expectancy';メモリ待ちで止まっているクエリの数(Memory Grants Pending)は無いか
メモリ待ちで止まっているクエリの数を確認します。
SELECT cntr_value as メモリ待ちのクエリ数
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Memory Grants Pending';※1以上が継続する場合、クエリがメモリ待ちで停止している状態であり、パフォーマンスに直接影響するため優先的に対応が必要です。
メモリ診断情報を一括取得するスクリプト
これまで説明したメモリ診断に必要な情報を一括で取得するBATを作成する手順について説明します。
次のBATファイルを作成します。
上2行のサーバ接続情報、CSV出力先を必要に応じて変更し、SJIS形式で保存してください。
なお、このBATはSQLServerに接続できるユーザが実行する想定となっています。
set SERVER=localhost\SQLEXPRESS
set OUTPUT=C:\temp\sql_memory_log.csv
set DB=master
REM ファイルが無ければヘッダ作成
if not exist "%OUTPUT%" (
echo 取得日時,物理メモリ合計KB,OSから見た空きメモリKB,理想のメモリKB,確保しているメモリKB,PageLifeExpectancy秒,メモリ待ちのクエリ数 > "%OUTPUT%"
)
REM -s ",":CSV区切り、-W:余計な空白削除、-E:Windows認証、
sqlcmd -S %SERVER% -d %DB% -E -s "," -W -h -1 -i memory.sql >> "%OUTPUT%"次のSQLを上のBATファイルと同じ場所に「memory.sql」という名前にして、SJIS形式で保存します。
SET NOCOUNT ON;
SELECT
GETDATE() AS 取得日時,
sm.total_physical_memory_kb AS 物理メモリ合計KB,
sm.available_physical_memory_kb AS OSから見た空きメモリKB,
opm1.cntr_value AS 理想のメモリKB,
opm2.cntr_value AS 確保しているメモリKB,
ple.PageLifeExpectancy秒,
mgp.メモリ待ちのクエリ数
FROM sys.dm_os_sys_memory sm
CROSS JOIN (
SELECT cntr_value
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Target Server Memory (KB)'
) opm1
CROSS JOIN (
SELECT cntr_value
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Total Server Memory (KB)'
) opm2
CROSS JOIN (
SELECT MAX(cntr_value) AS PageLifeExpectancy秒
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Page life expectancy'
) ple
CROSS JOIN (
SELECT cntr_value AS メモリ待ちのクエリ数
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Memory Grants Pending'
) mgp;
tempdbデータファイルの分割
tempdbはソート処理や一時テーブル・テーブル変数などに使用される領域です。
tempdbで問題になるのがページの競合(ラッチ競合) です。
単一データファイルだと、複数スレッドが同じ管理ページに集中アクセスしてボトルネックになります。
tempdb数の目安は次のとおりです。
- 論理プロセッサの数が 8 以下の場合は、同じ数のデータ ファイル
- 論理プロセッサの数が 8 より多い場合は、8 つのデータ ファイル
- tempdb 割り当ての競合が引き続き発生する場合は、競合が許容できるレベルに減少するか、ワークロードに変更を加えるまで、データ ファイルの数を 4 の倍数で増やします。
tempdbの分割は次の場合に効果が出ます。
- 同時実行クエリが多い(並列処理)
- ソートやハッシュが多い重いクエリ
- tempdb 使用量が多い(実行計画で spills が出ている)
- ラッチによる待機が発生している
ラッチの確認
PAGELATCH_UP / PAGELATCH_EX が多い場合、tempdbを追加すると効果が出る可能性があります。
SELECT * FROM sys.dm_os_wait_stats WHERE wait_type LIKE 'PAGELATCH%';tempdb追加手順
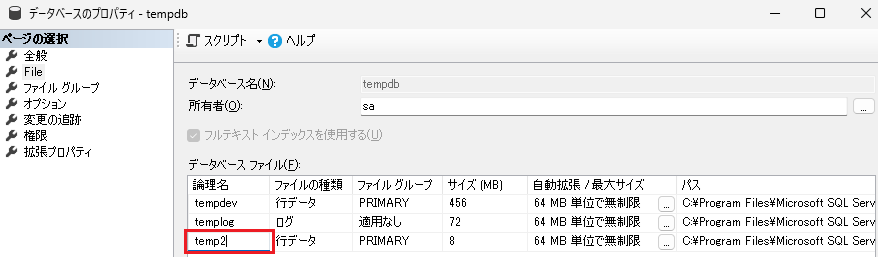
- SSMSでtempdbのプロパティを開く
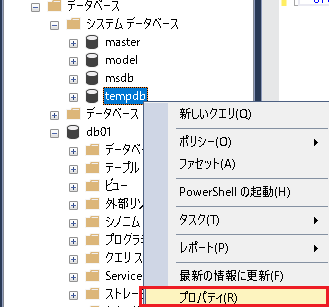
- 左のメニューから「File」を選択
- 「追加」をクリック
- 論理名に名前を入力
最初に保存したBATを実行するとCSV形式で保存されます。

その他、負荷を下げる方法
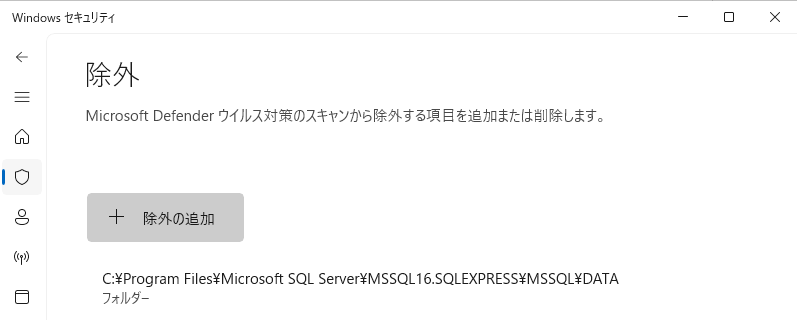
ウィルス対策ソフトのリアルタイムスキャン除外
SQL Serverのデータファイル(.mdf)やログファイル(.ldf)に対し、ウィルス対策ソフトのリアルタイムスキャンを除外することで、データの読み書きが早くなる場合があります。
WindowsDefenderの設定例(ファイル保管先が「C:\Program Files\Microsoft SQL Server\MSSQL16.SQLEXPRESS\MSSQL\DATA」の場合)


コメント