
ITサービスにおける可用性管理は、信頼性・顧客満足に直結する重要な要素です。
本書は可用性管理の目的、活動内容を説明します。
可用性維持を実現するためには信頼性の基礎も知っておく必要がありますので、この内容も知っておいてください。

可用性管理とは
可用性とは
可用性はシステムが必要なときにちゃんと使える状態であることを指します。
コンビニで例えると・・・
24時間営業でいつ行っても開いているコンビニは「可用性が高い」状態です。
一方、よく閉まっていたり、レジが止まって買い物できない状態は「可用性が低い」と言えます。
可用性は信頼性と似ていますが、次の違いがあります。
- 可用性:使いたいときに使えるか
- 信頼性:正常に動き続けるか
可用性は「利用できる状態」に注目し、信頼性は「壊れずに動き続けること」に注目しています。
可用性管理の目的
可用性管理の目的は、サービスを使いたいときに使える状態に維持することであり、そのためにサービスの可用性を最適化、改善していくことです。
可用性管理の活動内容
可用性管理は次の流れとなります。
- リスクアセスメント
- 要求事項を挙げる
- 目標を決める
- 設計と実装
- 監視と評価
- 目標未達成の場合の処置(改善)
各活動について説明をします。
①リスクアセスメント
システム停止など可用性を脅かす要因(リスク)を評価(アセスメント)して文書化します。
本活動は決められた間隔で行うのが望ましいです。
情報資産の特定
先ずはどのような情報資産(会計データ、顧客情報、契約情報など)があるかを特定します。
リスクの特定
リスクを特定します。リスクは以下の例がります。
- ハードウエア故障
- 停電
- サービス停止
- データ破損
- 外部からの不正アクセス
- OSやミドルウエアの脆弱性が発覚
- ソフトウェアのバグや不具合
- キャパシティオーバー(利用者やデータ量が増大)
リスクのアセスメント
リスクのアセスメントは、リスクが発生する可能性(頻度)や影響(重大度)で評価します。
先ほど挙げたリスクの例の一部に対し、アセスメントの例を挙げます。
- ハードウエア故障
頻度:中
影響度:高(サーバダウンの場合はシステムが停止し、業務も停止する。) - 停電
頻度:低(利用しているデータセンターにはバックアップ電源が備えられている。過去20年間停電は無い。)
影響度:高(サーバダウンの場合はシステムが停止し、業務も停止する。) - サービス停止
頻度:中
影響度:高(システムダウンの場合はシステムが停止し、業務も停止する。) - :
②要求事項を挙げる
可用性管理で必要となる基本的な要求事項を挙げます。
要求事項は主に次の内容があります。
- 稼働時間
例:365日、24時間だが、1か月あたり1日だけ計画停止を許容する。 - 稼働率
例:年間稼働率:99.99%
※メンテナンスなど計画停止期間を除くことを明記する。
対象時間は、24時間/365日なのか営業時間なのか、測定期間は年なのか月なのかも決める。 - 計画停止期間
例:メンテナンス作業などによる計画停止は、8時間/月とし、利用者の営業時間外とする。 - パフォーマンス基準
例:各画面の応答時間は3秒以内であること。 - 許容ダウンタイム
例:利用者の営業時間内の許容ダウンタイムは4時間とする。 - バックアップ
データは常にバックアップされ、復旧可能であること
③目標を決める
要求事項を基に、システムレベルでの目標を決めます。
- 稼働時間
サービスの年間稼働率を99.9%以上に設定する。計画停滞期間を年間で最大8時間に抑える。 - 稼働率
ービスの稼働率を99.99%以上に維持する。これにより、年間のダウンタイムは52.56分以内に抑え、予期しない停止を最小限にする。 - 計画停滞時間
メンテナンスや計画停滞は月に最大8時間以内で実施し、営業時間外に実施してユーザーへの影響を最小化する。 - パフォーマンス
サービスのレスポンスタイムを常に3秒以内に保ち、ユーザーのパフォーマンスに対する不満を防ぐ。 - バックアップ
データバックアップは毎日自動で実施し、データ復旧テストを行い、復旧時間(RTO)は1時間以内に設定する。
ここで決めた目標がKPIとなります。
④設計と実装
具体的にサーバ構成を決めたり、バックアップソフトの選定と設計(設設定)をしたりします。
ここでは具体的な詳しい内容の説明はありませんが、次のように決めていき、実装もします。
- 冗長化システムの設計
- アプリケーションサーバ
アプリケーションサーバは3台構成とし、2台までは故障してもアプリケーションサーバの利用を可能とする。
電源、ネットワークカードは冗長化する。
ストレージはRAID6とする。 - データベースサーバ
アプリケーションサーバは2台構成
電源、ネットワークカードは冗長化する。
ストレージはRAID6とする。
- アプリケーションサーバ
- バックアップと復旧システムの構築
- アプリケーションサーバはバックアップソフトを使い、メンテナンス直前と直後にバックアップをする。
加えて、災害復旧(DR)計画を策定し、いざという時に迅速にデータを復旧できる仕組みを作る。 - データベースサーバはデータベースのバックアップ機能を使い、日次でバックアップを取得する。
- アプリケーションサーバはバックアップソフトを使い、メンテナンス直前と直後にバックアップをする。
- :
この活動では次の監視と評価で必要になる、監視に必要な設計と実装もします。(監視ツールの選定、導入、設定)
⑤監視と評価
監視
監視は監視ツールによってリアルタイムで問題発生時に即座にアラートが通知される仕組みとなっている必要があります。
パフォーマンスについても、手動あるいはRPAを用いて定期的に画面の応答側をを記録したり、バッチ処理の処理時間を記録したりします。
評価
システムやサービスの稼働率、レスポンスタイム、バックアップ成功率などのKPIをレビューします。
可用性を高める方法
- 冗長化(システムを二重化する)
Webサーバを2台以上にしたり、データベースをレプリケーション構成にしたりして、一部で障害が起きても継続して利用できるようにしておきます。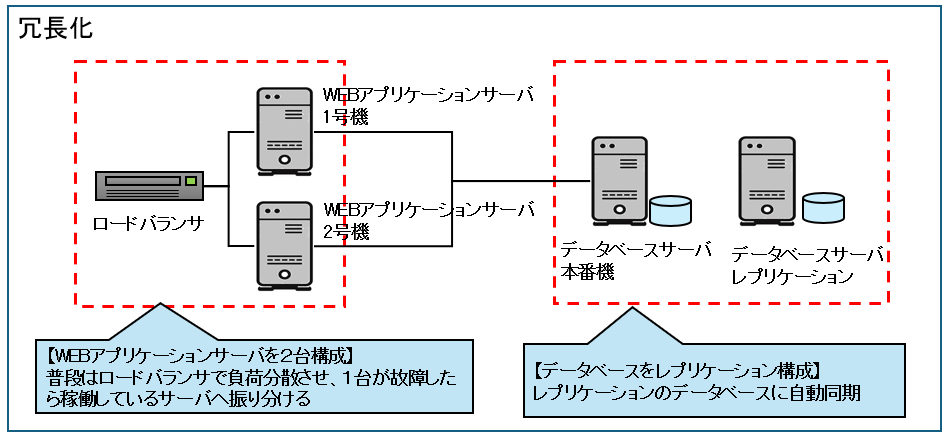
- 監視とアラート
監視ツールでサーバの死活監視(Ping/HTTP)、CPU・メモリ使用、レスポンス計測、エラーログなどシステムを監視し、異常となる前または、異常を検知したらすぐ通知(アラート)が出るようにします。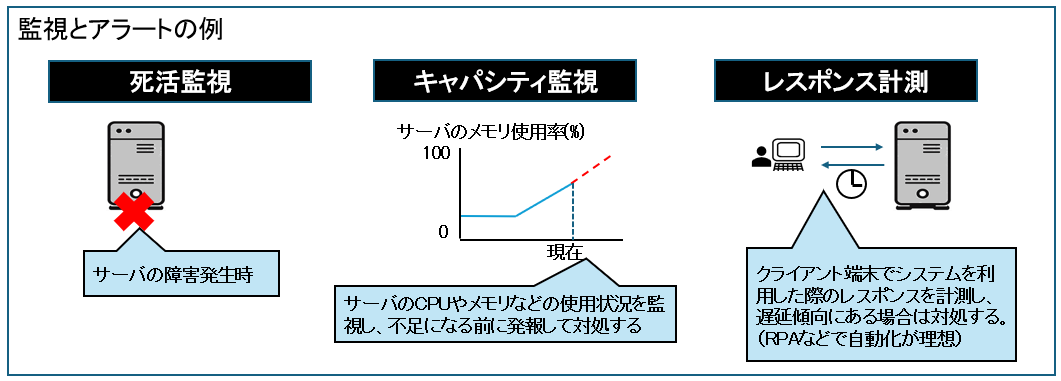
- バックアップとリストア設計
データ消失や障害に備えて、バックアップを取得します。 - フェイルオーバー設計
障害発生時に、自動的に別のシステムへ切り替える仕組みです。 - キャパシティプランニング
システム利用者数やデータ容量を監視し、これらの増加による停止を防ぐため、リソースを見積もります。 - 定期的なテストと訓練
定期的に障害復旧訓練をしておくことで、実際に障害が発生した場合でも迅速に対応ができます。
まとめ
- 目的:サービスを利用したいときに常に利用できる状態を維持するため、可用性を最適化・改善し続けることが目的。
- 主な活動の流れ:リスクアセスメント → ②要求事項の整理 → ③目標設定 → ④設計と実装 → ⑤監視と評価 → 必要に応じた改善、というサイクルで進める。
- リスクアセスメント:情報資産と可用性を脅かすリスク(例:ハード故障、停電、外部攻撃など)を特定・評価し、頻度と影響度を文書化して定期的に見直す。
- 要求事項・目標設定:稼働時間・稼働率・計画停止・応答速度・バックアップなどの要求を明確化し、これを基に具体的なKPI(例:稼働率99.99%、RTO1時間以内など)を設定する。
- 設計・監視・改善:冗長構成やバックアップ体制を設計・実装し、監視ツールでリアルタイム監視とKPI評価を行い、目標未達時には原因分析と改善を実施する。


コメント