AIプロジェクトにおける進め方を解説します。企画・PoC・開発それぞれのGo/No-Go判断基準を初心者にも分かりやすく整理します。
AIプロジェクトとは
「AIプロジェクト」はいろいろなとらえ方がありますが、一般的にデータとモデルを使って業務課題を解決する仕組みを作ることです。
例えば、売上予測をしてくれるAI、不正メールを自動で仕訳けてくれ李AI、社内FAQに答えるAIなどです。
自社向けのモデル(LLM)を作る場合もあれば、既存のモデル(ChatGPTなど)を使って実現する場合もあります。
AIプロジェクト進め方 全体像
AIプロジェクトは大きく4つの工程からなります。
- 企画・アセスメント
- ビジネス理解
- データ理解
- Poc
- 試作、評価
- 開発・実装
- 本番用のモデルを構築して本番稼働
- 運用保守
- 再学習や追加学習
AIプロジェクト進め方 工程の詳細
企画・アセスメント
ビジネス理解
課題・目的の定義
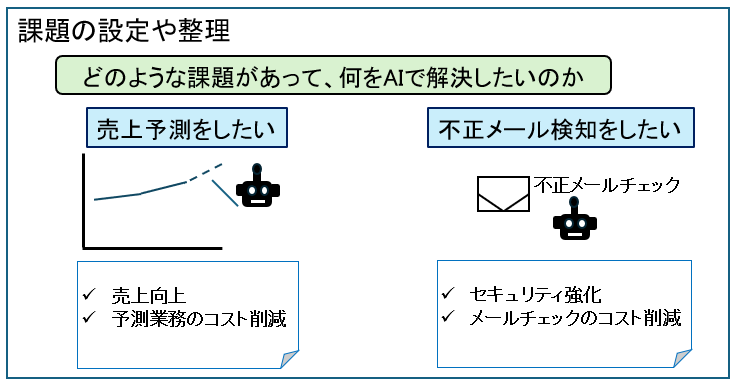
まずは、どのような課題があって、どれをAIで解決したいのかを決めます。ここが曖昧だと、プロジェクトは失敗する可能性が高くなります。
KPIや成功条件の定義
AIを導入することによるKPIと、成功条件の定義をする。
<例>
・売り上げが30%アップ
・業務コスト20%削減
AIプロジェクトで注意したいのは、「AIは目的ではなく手段」だということでです。
例えば上の「売上向上」の例ですと、仮にAIの精度は95%を実現できたとしても、目的である「売上向上」ができていなければ失敗です。
データ理解
先ほどの章で説明した課題を解くためのデータがあるかを確認します。
確認すべき点は次の通りです。
- 電子データとして存在するか
- 必要な属性はあるか
- 十分な件数はあるか
- 信用できるデータか(欠損値や外れ値の確認)
<レポートの作成例>
| 内容 | 記載例 |
|---|---|
| データ概要 | 件数・期間 : 約10万件(過去10年分の全社員宛てのメール) ラベルの有無 : 社員からの不正メールとして報告されたメールと自動仕分けによるラベル有り |
| データ品質 | ・社員からの不正メールとして報告されたメールは信用できる。 ・自動仕分けによるメールは一部で誤りがある。 ・約3万件のメールに本文の欠損がある。 |
| 課題 | ・クラス不均衡(不正が4%) ・本文の欠損が多い ・ラベルの誤り疑いあり ・日本語と英語が混在 |
| Go / No-Go判断 | 判断:Go 理由: ・ラベル付きデータあり ・不正メールに特徴的なパターンあり ・ただしクラス不均衡対策が必要 |
企画・アセスメントのGo/No-Go判断
Go/No-Go判断としては「やる価値あるか」になります。
| 判断基準 | ポイント |
|---|---|
| ビジネス価値 (重要) | ■KPIが明確か ■改善インパクトが定量化できるか <例> Goの例:売上30%アップ No-Goの例:売上アップ(抽象的すぎ) |
| AI適用性 | ■予測・分類の問題に落ちているか ■従来のやり方(ルールベース等)で十分ではないか |
| データ成立性 | ■データが存在するか ■ラベルがあるか(教師ありの場合) |
Poc
Pocとは
AIプロジェクトにおけるPoC(Proof of Concept)は、「技術的・ビジネス的に成立するか」を小さく・早く検証するフェーズです。
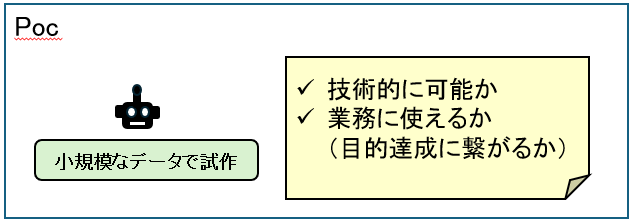
Pocの進め方
| 作業名 | 実施内容 |
|---|---|
| コンセプト決め | ①先ほどの章で設定した、ビジネス課題を基に「何のためのAIか」をはっきりさせます。 ②成功指標(KPI)の設定 <例> ・精度:不正メール検知率90% ・業務改善効果:50%時間削減 ③スコープ PoCは小さく始めるのが一般的です。 (短期間(数週間〜数ヶ月)で検証) ④評価設計 ・どのデータで検証するのか ・何を評価するのか(人の作業、不正メール検知率) |
| データの準備 | 以下の確認をします。 ・Pocに必要なデータが存在するか ・データ量は十分か ・欠損・偏り・ノイズの状況 ・個人情報や利用制約の有無 |
| Poc設計(手法・モデル決め) | ・既存APIの利用(例:LLM、画像認識APIなど) ・機械学習モデルの選定(分類、回帰、生成など) ・既存モデルのファインチューニング or ゼロショット |
| プロトタイプ作成 | ■ポイント ・コア機能のみ実装 ・画面は簡易でOK(Mok) ・手作業との組み合わせも許容(完全自動化は不要) ■AIロジックの組み込み ・API連携(LLMなど) or モデル実装 ・推論処理の実装 ・パラメータ調整(プロンプト含む) |
| テスト実行 | ・想定ケースでの動作確認 ・エッジケース(例外)の確認 ・業務フローに沿った通しテスト |
| アウトプット作成 | ・テスト結果(ログ・精度評価) ・課題リスト ・改善案(次フェーズへの示唆) |
PocののGo/No-Go判断
| 判断基準 | ポイント |
|---|---|
| KPI達成見込み (重要) | ■目標精度に届くか ■ビジネスインパクトが出るか <例> Goの例:不正メール検知率が90% |
| 技術的成立性 | ■モデルが安定して動くか ■学習・推論時間が現実的か No-Goの例:推論に10分かかる |
| コスト対効果 | ■開発コストに見合うか ■運用コストが高くならないか |
Pocの結果、本当に効果が出るのかを判断します。
開発・実装プロセス
AIプロジェクトにおける開発はアジャイル開発が一般的です。
理由は次の通りです。
- どんなデータが集まるか分からない
- モデルの精度が事前に読めない
- やってみないと価値が出るか分からない
すべてアジャイル開発で行うのが最適ではありませんが、反復を繰り返して良いモノに仕上げていきます。
アジャイル開発の説明は「開発手法の説明」を参照してください。
開発で実施する内容は次の通りです。
- モデル選定(回帰 / 分類 / クラスタリング)
- 評価指標(Accuracy / F1 / RMSE)
- 過学習・バイアス
運用保守
通常のAIではないシステムの場合は、開発が完了したシステムは運用(更新プログラム適用、バッチ処理、データメンテナンスなど)を行いますが、AIシステムも運用作業があります。
AIのシステムは、従来システムとの違い、時間の経過とともにデータの質が変化し、精度が低下していく可能性があります。
予測モデルを効率良く、高い品質で運用していくことが重要です。
MLOpsとは
MLOps(Machine Learning Operations)機械学習(Machine Learning)と運用(Operation)を組み合わせた造語です。
具体的には、データ分析・前処理/特徴量作成・モデルの学習・モデルの評価、デプロイ、モニタリングといった一連のプロセスを継続的かつ自動化された形で管理します。
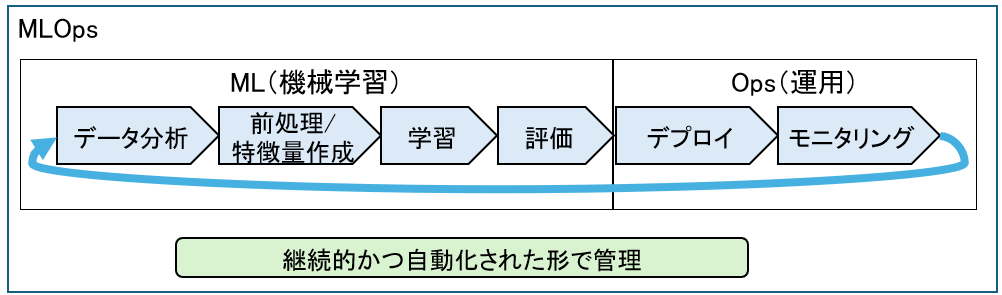
- データ分析・・・課題認識、要件定義
- 前処理/特徴量作成・・・モデルが学習しやすい形にデータを整える
- モデルの学習・・・アルゴリズムの選定(回帰、分類など)、学習データを使ってモデルを訓練
- モデルの評価・・・テストデータで精度を測定し、モデルが実際に使える性能か判断する
- デプロイ・・・モデルをAPIやバッチ処理として実装
- モニタリング・・・予測精度の監視、入力データの変化を検知、システムの状態監視(遅延・エラー)
まとめ
- AIプロジェクトは「企画 → PoC → 開発 → 運用」の流れで進む
- 最初にビジネス課題とKPIを明確化することが重要
- データの質・量が成果を大きく左右する
- PoCは「実現可能性の検証」であり、目的化しない
- Go/No-Go判断を適切に行い、無駄な投資を防ぐ
- モデル精度だけでなく、業務への適用性を重視する
- 本番環境では性能・コスト・安定性のバランスが重要
- MLOpsにより継続的な改善と監視を行う
- 運用後もデータ変化(ドリフト)への対応が必要
- 小さく始めて段階的にスケールアップさせるのが成功のコツ
腕試し(理解テスト)
腕試し(理解テスト)に挑戦する場合はこちらをクリック。

コメント