基本情報技術者試験のデータベース設計を図解でわかりやすく解説します。
データ分析、ER図、カーディナリティ、主キー・外部キー、正規化(第1~第3正規形)まで、初学者向けに丁寧に説明します。
データベース設計とは
データベース設計とは、必要なデータを整理し、効率よく管理・利用できるデータベースを作るための作業です。
もし、正しい設計を行わずにデータベースを作成すると、同じデータを何度も登録したり、更新漏れが発生したりして、データの整合性が保てなくなる可能性があります。
そのため、データベースは実際に作成する前に、必要なデータやデータ同士の関係を整理し、適切な構造を設計することが重要です。
データ分析
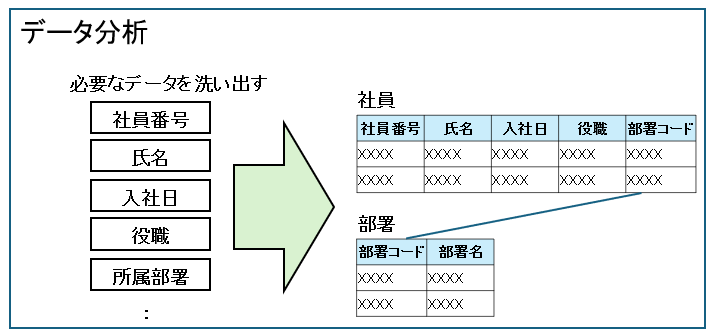
データ分析とは、データベースを設計する前に、どのようなデータが必要かを整理・分析する工程です。
例えば、社員管理システムを作成する場合は、社員番号・氏名・部署・入社日など、管理すべきデータを洗い出し、データ同士の関係を整理します。
メタデータとは
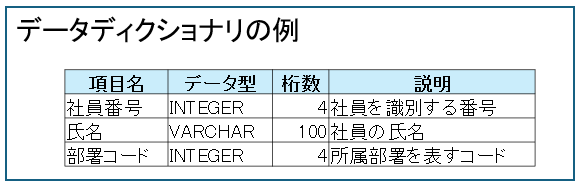
メタデータ(Metadata)とは、データを説明するためのデータのことです。
例えば、社員番号「1001」や氏名「山田 太郎」はデータですが、以下の情報はメタデータです。
- 社員番号
- 項目名は「社員番号」
- データ型は「整数」
- 桁数は「4桁」
- 主キーである
- 氏名
- 項目名は「氏名」
- データ型は「文字」
- 桁数は「100桁」
データディクショナリとは
データディクショナリとは、DBMSが管理するデータ、利用者、プログラムに関する情報、およびそれらの関係を保持するデータの集合体です。
分かりやすく説明すると、データベースで使用するメタデータを一覧として管理したものです。
データベース設計の流れ
データベース設計では、いきなりテーブルを作成するのではなく、段階的に設計を進めます。
基本情報技術者試験では、特に概念設計 → 論理設計 → 物理設計の流れを理解しておくことが重要です。
設計の流れは次のようになります。
- データ分析
必要なデータやデータ同士の関係を整理します。 - 概念設計
データベース全体の構造を考えます。 - 論理設計
テーブルや主キー・外部キーの設計と正規化をします。 - 物理設計
データをどのように保存するかを決めます。
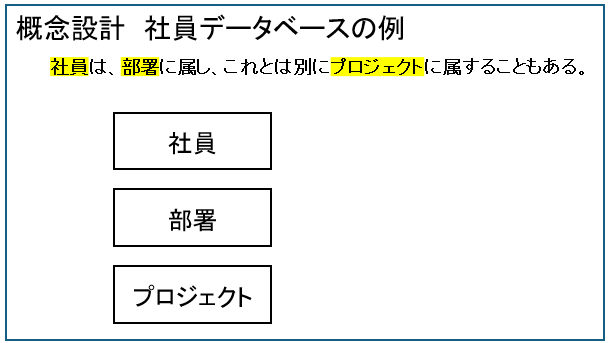
概念設計とは
概念設計とは、現実世界の情報を整理し、データ同士の関係を設計する工程です。
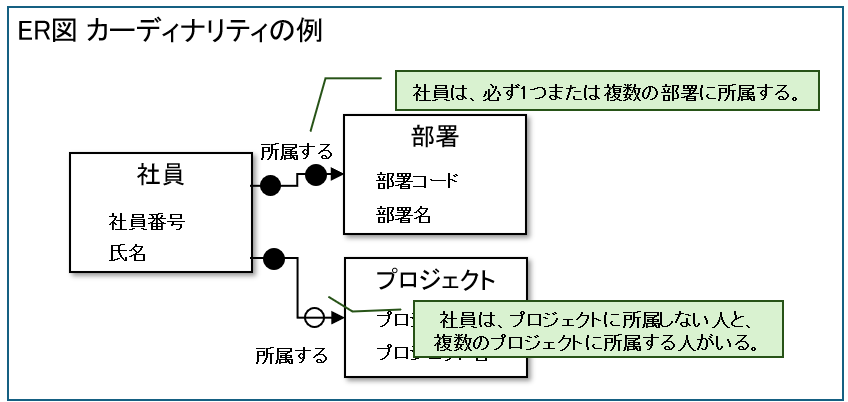
下の図は社員データベースの設計例で、社員、部署、プロジェクトという情報を扱うという内容になっています。
このような管理する情報(社員、部署など)をエンティティと言います。
ER図とは
ER図(Entity Relationship Diagram)とは、データ同士の関係を図で表したものです。
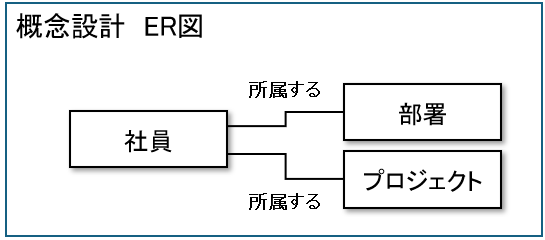
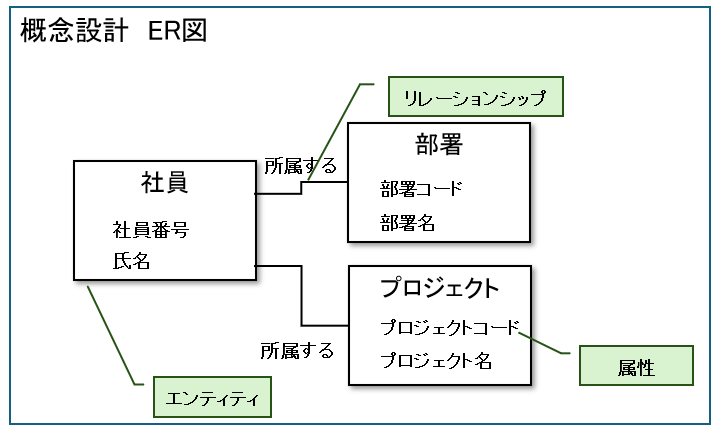
最終的なER図は、次の3つの要素を使用します。
- エンティティ(Entity):管理する対象(社員、部署、商品など)
- 属性(Attribute):エンティティが持つ情報(社員番号、氏名、部署名など)
- リレーションシップ(Relationship):エンティティ同士の関連
カーディナリティとは
カーディナリティとは、エンティティ同士が1:1なのか、1:多なのかを表す考え方です。
カーディナリティの表記方法はいくつかりますが、情報技術者試験では以下の表記が使われます。
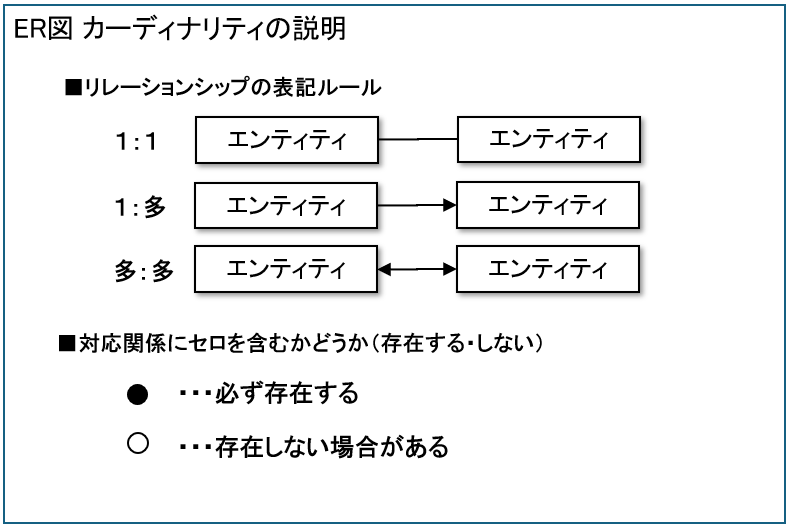
先ほどの社員データベース設計の例に適用すると以下のようになります。
論理設計とは
論理設計とは、概念設計で整理した内容を、実際のテーブルとして設計する工程です。
主キーとは
主キー(Primary Key)とは、テーブル内の各データを一意に識別するための項目です。
例えば、社員テーブルでは「社員番号」が主キーになります。
<主キーの特徴>
- 同じ値を登録できない(重複不可)
- NULL(値なし)を登録できない
- 1つのレコードを一意に識別できる
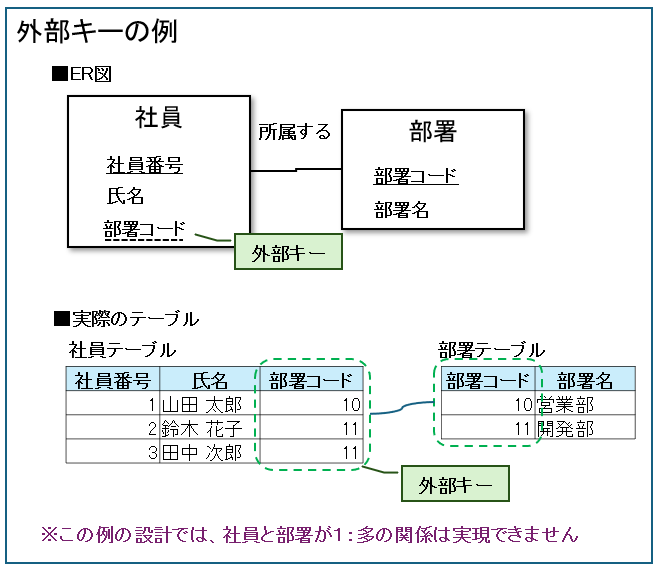
外部キーとは
外部キー(Foreign Key)とは、他のテーブルの主キーを参照する項目です。
例えば、社員テーブルの「部署コード」は、部署テーブルの主キーを参照しています。
一意性制約とは
一意性制約(UNIQUE制約)とは、同じ値が重複して登録されないようにする制約です。
例えば、社員番号やメールアドレスは、同じ値を複数の利用者に割り当てることはできません。
そのため、一意性制約を設定して重複登録を防ぎます。
正規化とは
正規化とは、データの重複をなくし、更新や削除の際に不整合が発生しないようテーブルを整理する作業です。
正規化は論理設計で行われ、第1正規形、第2正規形、第3正規形の順に整理していきます。
関数従属とは
正規化の説明を始める前に「関数従属」を理解しておく必要があるので説明します。
関数従属とは、ある項目の値が決まると、別の項目の値も一意に決まる関係のことです。
部分関数従属とは
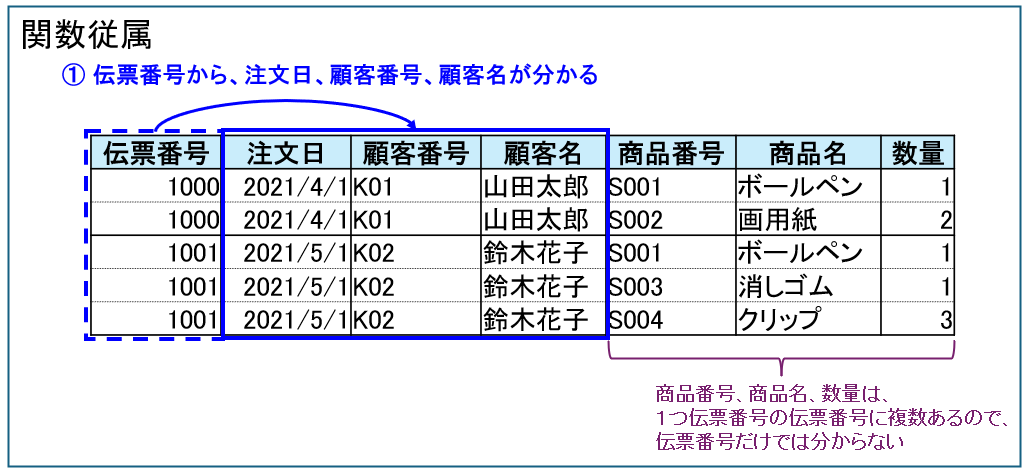
次の例は商品の注文の例です。
まず、伝票番号から、注文日、顧客番号、顧客名が分かります。
このような関係を関数従属といいます。
他にも、伝票番号と商品番号から数量が分かり、
商品番号から商品名が分かります。
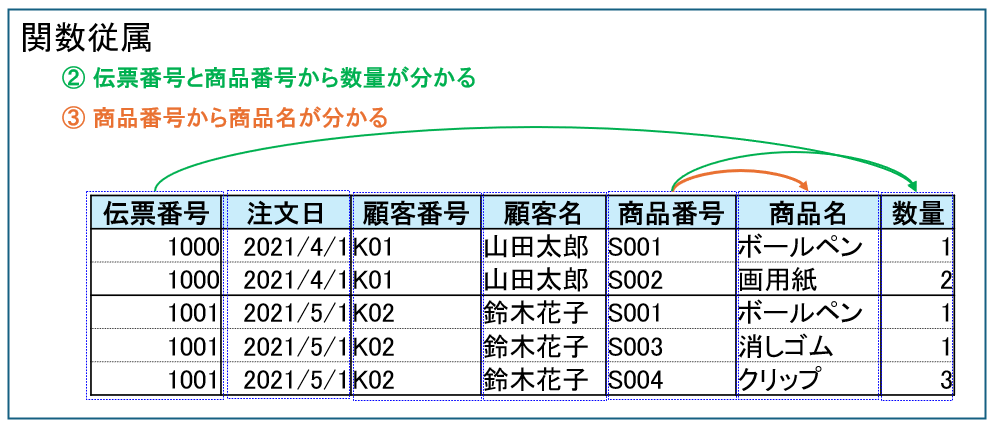
この例のでは、伝票番号と商品番号の2つがあれば、全項目が分かる(特定できる)ので、伝票番号と商品番号がキーになります。
しかし、「注文日」は「伝票番号」だけでも分かりますし、「商品名」も「商品番号」だけで特定できます。
・伝票番号 → 注文日
・商品番号 → 商品名
このように、複数の列で構成される主キーの一部の列によってのみ決まる状態を部分関数従属性と言います。
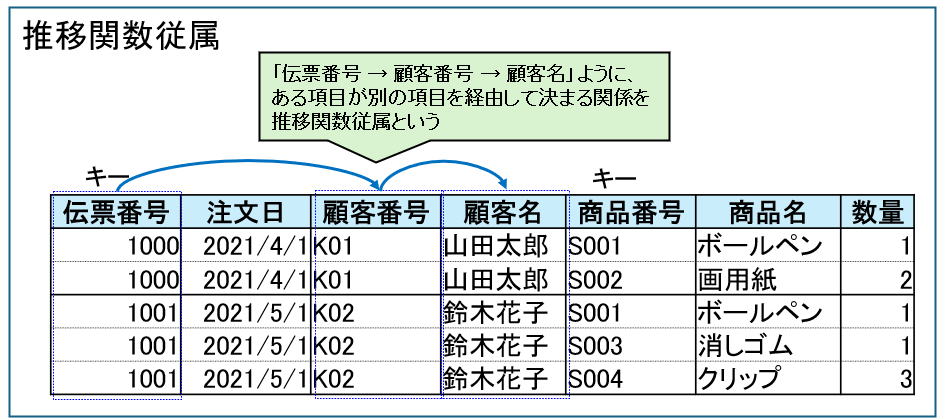
推移関数従属とは
先ほどの部分関数従属説明の章で使用した表には部分関数従属とは別の問題もあります。
顧客名は主キーである「伝票番号+商品番号」のどちらにも直接依存しているわけではありません。
・伝票番号 → 顧客番号
・顧客番号 → 顧客名
そのため、「伝票番号」が分かると「顧客番号」が分かり、さらに「顧客番号」が分かると「顧客名」が分かります。
この「伝票番号 → 顧客番号 → 顧客名」ように、ある項目が別の項目を経由して決まる関係を推移関数従属といいます。
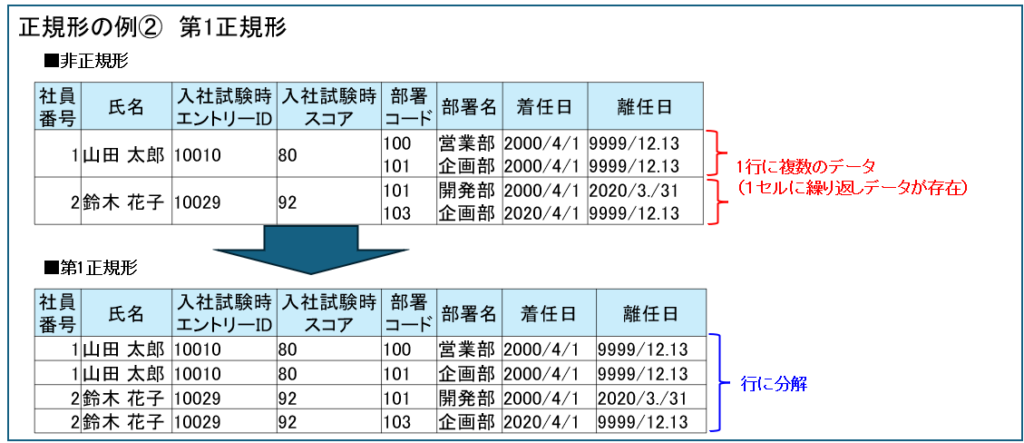
第1正規形
第1正規形とは、1つのセルには1つの値だけを格納する形です。
例えば、次の社員データベースの例のように、1つのセルへ複数の所属部署情報を保存するのは、第1正規形ではありません。

第1正規形は、1つのセルには1つの値だけを保存(繰り返し項目をなくす)ことをします。
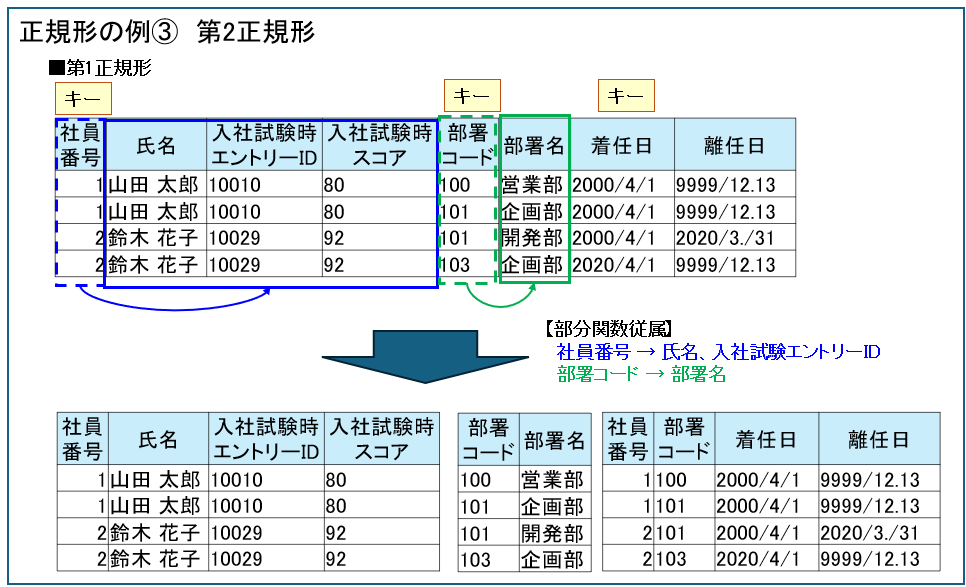
第2正規形
次にキー項目がどれなのかを特定します。
さきほどの第1正規化済みの社員データベースの場合、社員番号、部署コードがキー項目になりそうですが、これだけだと十分ではないです。
同じ社員が複数の部署に所属したり、過去の所属も管理しているので、「社員番号+部署コード+着任日」の組み合わせがキーとなります。
そして、部分関数従属は以下になります。
社員番号 → 氏名、入社試験エントリーID
部署コード → 部署名
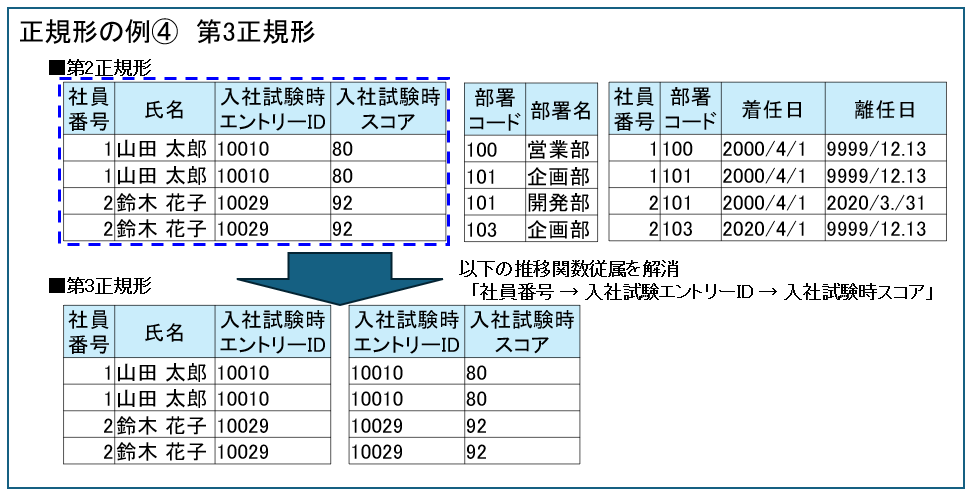
第3正規形
先ほどの表を見ると「社員番号、氏名、入社試験エントリーID、入社試験時スコア」ですが
・社員番号 → 入社試験エントリーID
・入社試験エントリーID → 入社試験時スコア
が成り立ち、「社員番号 → 入社試験エントリーID → 入社試験時スコア」という推移関数従属があります。
推移関数従属を解消するため、
・社員番号、氏名、入社試験エントリーID
・入社試験エントリーID、入社試験時スコア
に分割します。
腕試し(理解テスト)
腕試し(理解テスト)に挑戦する場合はこちらをクリック。


コメント