
ニューラルネットワークアーキテクチャの一種である、トランスフォーマーは高い精度でかつ高速に自然言語処理が可能です。
本書はトランスフォーマーのエンコーダ、デコーダ、Self-Attentionなどの仕組みを簡単なイメージで説明します。
本書は機械学習の基礎を学習済みであることを前提に書いています。
トランスフォーマーとは
トランスフォーマーとは何か
トランスフォーマー(Transformer (deep learning architecture))とは、生成AIでよく使われるモデル構造の一つです。
文章などのデータを処理するために開発された深層学習モデルで、現在の生成AIの基盤となっている技術です。
トランスフォーマーは Attention(注意機構)と呼ばれる仕組みを使い、文章の中で重要な単語同士の関係を効率的に捉えることができます。
トランスフォーマーができること
トランスフォーマーは
- 機械翻訳
- 文章生成
- 要約
- チャットAI
など、さまざまな自然言語処理タスクで高い性能を発揮します。
生成AIとトランスフォーマーの関係
生成AIとは
生成AIはデータを生成するAIで、文書、画像、音声を生成できます。
生成AIの大きな特徴として、「次に来る確率が最も高いものを予測する」というのがあります。
例:「今日はとても良い天気なので、公園に__」
ここに入る確率が高いのは・・・「行きました」、「雨が降った」、「車を買った」
⇒文脈を考えると「行きました」が最も自然。
このように、文脈から次の単語を予測するのが言語系生成AIの基本です。
なぜトランスフォーマーが使われるのか
トランスフォーマーは長い文章であっても、文章全体を同時に見ることができ、この単語は、文のどの単語と関係があるかを一気に計算できるのが利点です。
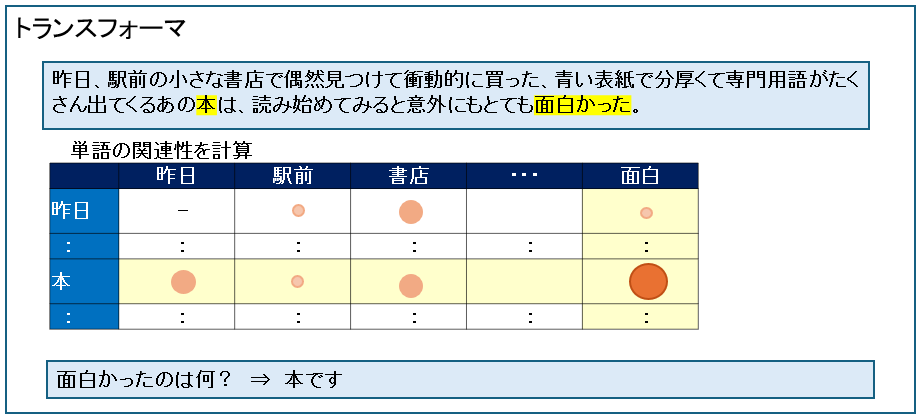
トランスフォーマーの仕組みをわかりやすく解説
全体の流れ
トランスフォーマは大きく分けると、トークン(単語)埋め込み層、位置エンコーディング、エンコーダ、デコーダ、線形層、softmax層で構成されています。

トランスフォーマーにはデコーダのみの構成もあり、ChatGPTなどの生成AIはデコーダのみです。
本書は、単語埋め込み層、位置エンコーディング、エンコーダ、デコーダ、線形層、softmax層の構成で説明します。
トークンとは
細かい説明に入る前にトークンの説明をします。
トークンとは、AIが文章を処理するときの「最小単位」のことです。
一見すると単語のように思えますが、実際には単語そのものとは限りません。
例えば、「私は学生です」は、
→ 「私」「は」「学生」「です」ではなく
→ 「私」「は」「学」「生」「です」のように分かれることもあります。
このようにトークンは、人間にとっての単語とは違い、AIが扱いやすい形に分割された単位になっています。
トランスフォーマ各層の概要
①埋め込み層
単語埋め込み層は各トークン(単語)を埋め込みベクトルという形で数値化します。
埋め込みベクトルはトークンの特徴量を高次元のベクトルで表現したものです。
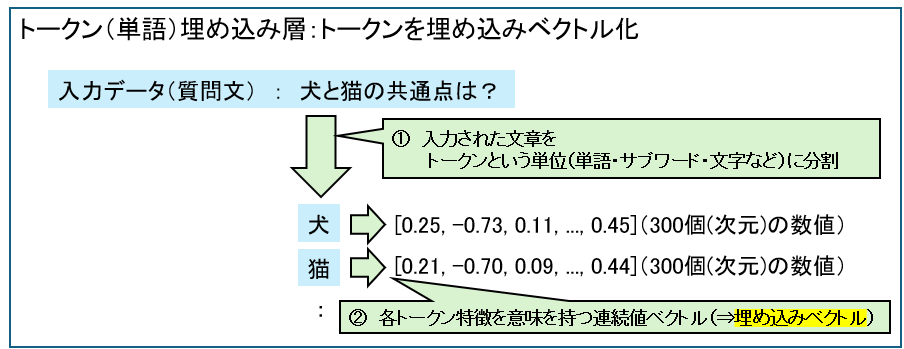
埋め込みベクトルを分かりやすく説明すると、例えば次のように犬と猫と自動車の特徴を「動物らしさ」や「感情の豊かさ」で表現すると犬と猫は似ているということを説明したものです。

②位置エンコーディング(Positional Encoding)
位置エンコーディングは、各トークンに位置の情報を足します。
トークンの位置を把握することで、例えば「私は犬が好き」と「犬は私が好き」のようにトークンの位置が変わってしまうことを防ぎます。
位置エンコーディングは、位置番号から計算によって位置ベクトルを生成します。
内容としては、位置番号を複数の波(sin/cos)に変換しています。
計算式の詳細は省略しますが、この方式は位置を少しずらすと値がなめらかに変化する性質があります。
そのため、トークン埋め込みで得られた意味ベクトルに加算しても、学習を通して意味情報と位置情報をうまく統合できるようになっています。
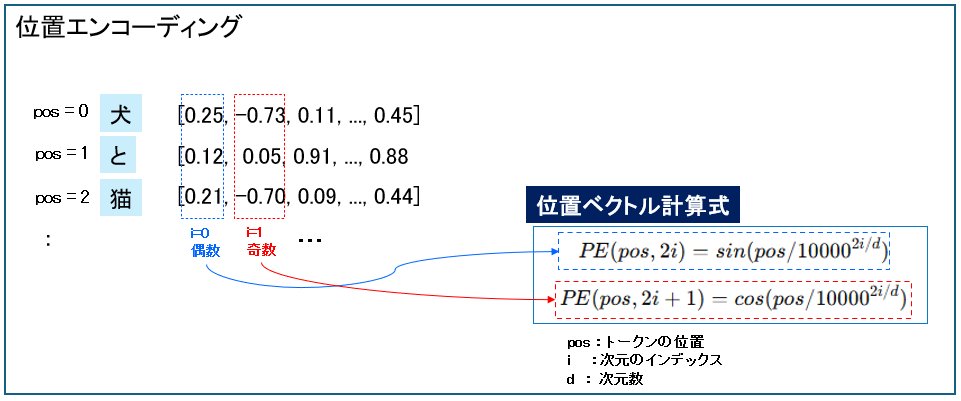
先ほどのトークン(単語)埋め込み層の結果に位置エンコーディングの結果を足して次のエンコーダに渡します。
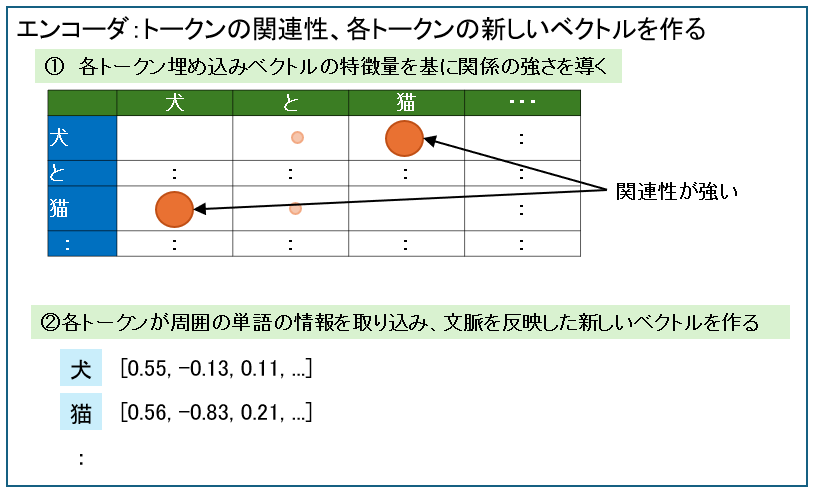
③エンコーダ
エンコーダは、入力文の意味を理解をします。
受け取った各トークンの関連性を導き、これを基に各トークンに対し新しいベクトルを作ります。
④デコーダ
デコーダは、理解した情報をもとに文章を生成します。
エンコーダからの情報(各トークンに文脈を反映したベクトル)と学習で得たパラメータ(重み)を使って、回答のトークンの確立を計算します。
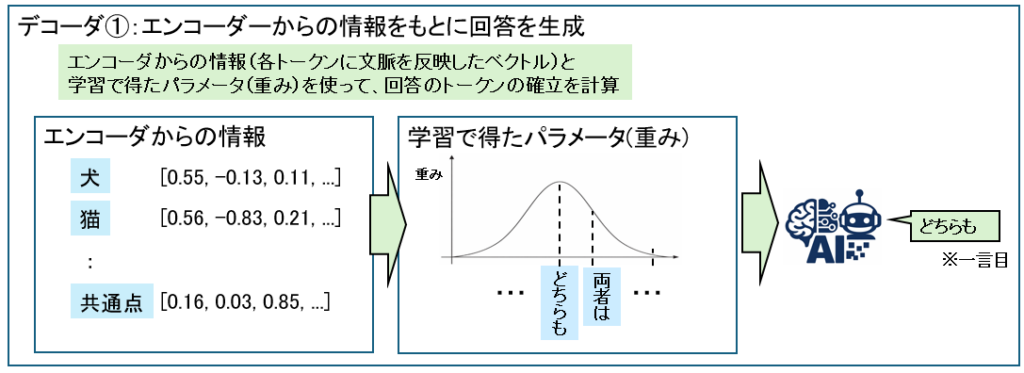
デコーダは自分が生成したトークンも使用してさらに生成をします。
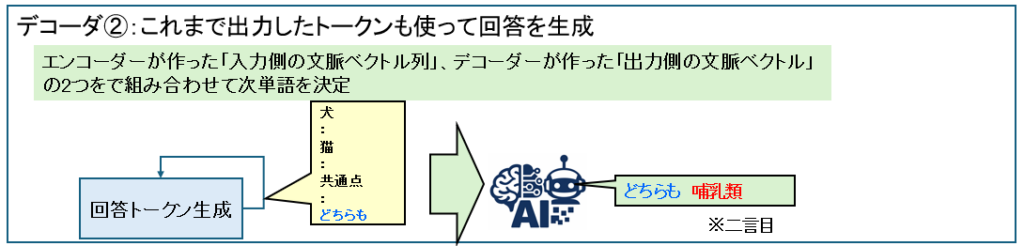
エンコーダの仕組み
エンコーダはSelf-Attention(自己注意)層と Position-wise Feed-Forward Networks(FFNN)という2つで構成されています。
Self-Attention(自己注意)層
Self-Attentionは、文中の各単語が他の単語にどれくらい関連しているか(重要度)を計算する仕組みです
Self-Attention層では、各トークンの埋め込みベクトルから、Q(Query)、K(Key)、V(Value)という3種類のベクトルを作ります。
- Query (Q) – 問い合わせ: 「現在の単語が、他の単語に対して何を探しているか」を示すベクトル。
- Key (K) – キー: 「その単語が、他の単語からの問い合わせに対し、どのような特徴を持っているか」を示すインデックスベクトル。
- Value (V) – 値: 「その単語が持つ実際の情報内容」を示すベクトル。
各トークンに対し、Q(Query)と、K(Key)の内積を求める。下の例は「共通点」と各キーの内積を計算しています。
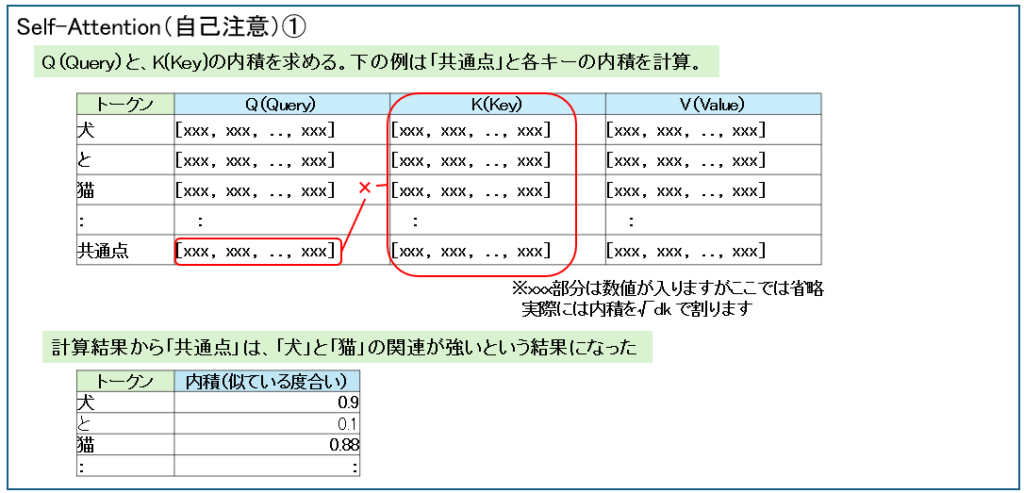
Softmaxで重み化し、これに重み付き合成(V(Value)を掛ける)で求められます。

全トークンについてもこの方法で計算をします。
Position-wise Feed-Forward Networks(FFNN)
Position-wise Feed-Forward Networks(FFNN)は各トークンをそれぞれ個別に深く変換する層です。

デコーダの仕組み
デコーダの構成はエンコーダに似ていますが、Self-Attention層とPosition-wise Feed-Forward Networks(FFNN)の間に、Encoder-Decoder Attention層(クロスアテンション)が存在します。
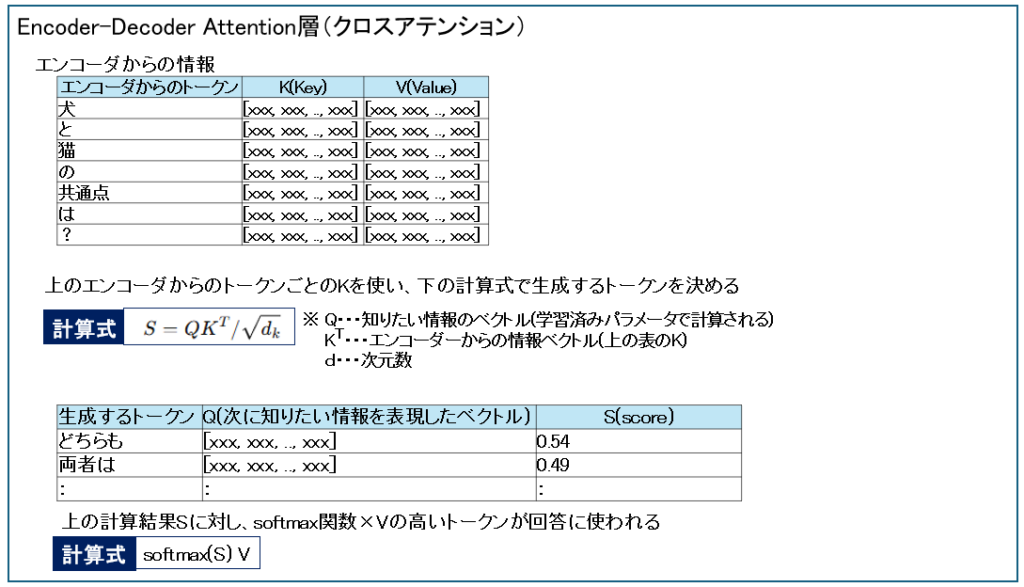
Encoder-Decoder Attention層(クロスアテンション)
エンコーダからのK(Key)と、生成するトークンのベクトルQをもとに、生成するトークンのScoreを算出します。
Q(Query) は デコーダの隠れ状態(Decoder Hidden State) から作られます。
Sに対しsoftmaxで「どの単語を見るかの割合」を決め、その割合でVを重み付き平均します。
トランスフォーマーのまとめ
- トランスフォーマー(Transformer)は自然言語処理でよく使われるモデルで、主に 入力 → 埋め込み → エンコーダ → デコーダ → softmax → 出力 の流れで処理する。
- トークン化により文章を単語やサブワードなどの単位に分割する。
- 各トークンは 埋め込み(Embedding)によって数値ベクトルに変換され、計算可能な形になる。
- 単語の意味は ベクトル空間で表現され、意味が近い単語ほどベクトルも近くなる。
- 位置エンコーディング(Positional Encoding)を追加することで、文章内の単語の順序情報をモデルに与える。
- エンコーダはトークン同士の関係を考慮しながら、新しい特徴ベクトルへ変換する。
- エンコーダ内部では Self-Attention(自己注意)により、文中の他の単語がどれだけ重要かを計算する。
- Self-Attentionでは各トークンから Query・Key・Value の3つのベクトルを作り、重要度スコアを算出する。
- Position-wise Feed Forward Network(FFN)が各トークンの特徴をさらに変換・強化する。
- デコーダではエンコーダの出力を参照する Encoder–Decoder Attention(クロスアテンション)を使い、次の単語を予測して文章を生成する。
腕試し(理解テスト)
腕試し(理解テスト)に挑戦する場合はこちらをクリック。


コメント