
Oracleデータベースは、万が一障害が発生してデータが破損しても、障害直前に復旧(これを「完全リカバリ」という)ができるようデータ更新と同時にログを記録しています。
この大事なログですが、仕組みが分かっていないとログで容量がいっぱいになってディスクがパンクしたり、いざというときに復旧ができなくなってしまいます。
今回はこのログの基礎を解説します。
REDOログ:データの変更を記録
Oracleデータベースは、データに対しての変更操作をすると、REDOログにその内容が記録されます。
もう少し細かく説明をすると、トランザクションがコミットされるタイミングでデータ変更記録がREDOログへ記録されます。
REDOログへの記録はLGWRというプロセスが担当します。
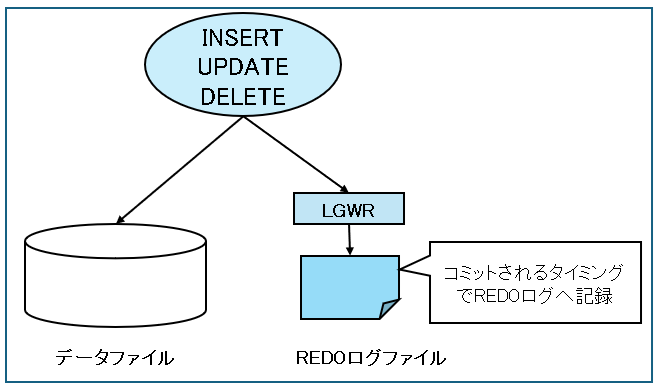
ログローテーション:ログが満杯になったら新しいログへ切替
REDOログファイルがいっぱいになると、Oracleは次のログファイルに書き込むために切り替えを行います。
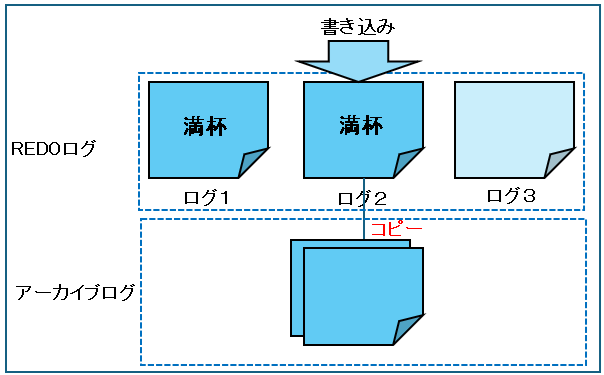
このREDOログファイルの切り替えをログローテーションといいます。この切り替えのことをログスイッチといいます。
下の例ではログ1、ログ2、ログ3の3つのログがあり、ログ1が満杯になったらログ2へと移り、ログ3が満杯になったらまたログ1へ戻ります。
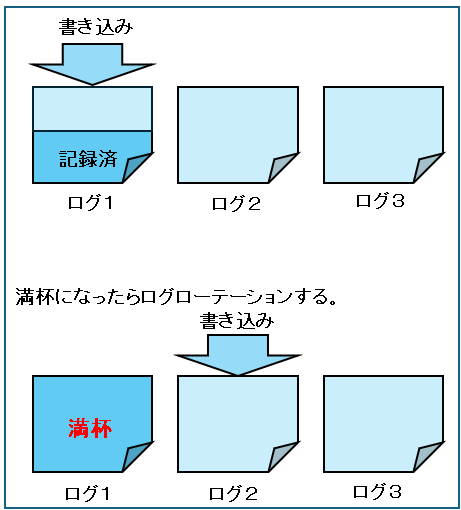
グループによるログの冗長化
REDOログが破損したり、ディスク障害によりREDOログが使えない状態になることを防ぐために、多重REDOログ、つまりREDOログの2つ以上の領域に同一のコピーを記録することができます。
下の図のように、多重化を実装するにREDOログファイルのグループを作成します。
ディスク障害に備えて、グループは異なるディスクに配置します。
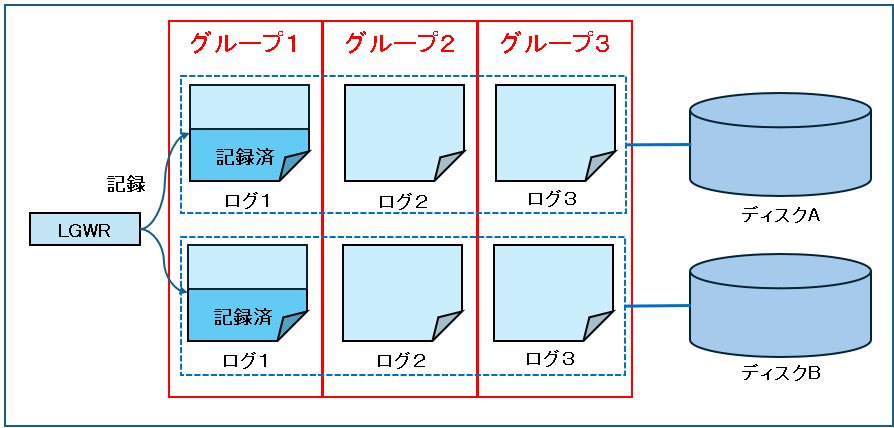
アーカイブログ:古くなったログをアーカイブ
使用可能な最後のREDOログ・ファイルが一杯になると、最初のREDOログ・ファイルに戻って書込みを行い、再び循環を開始しますので、ログスイッチする前のログが消えてしまいます。
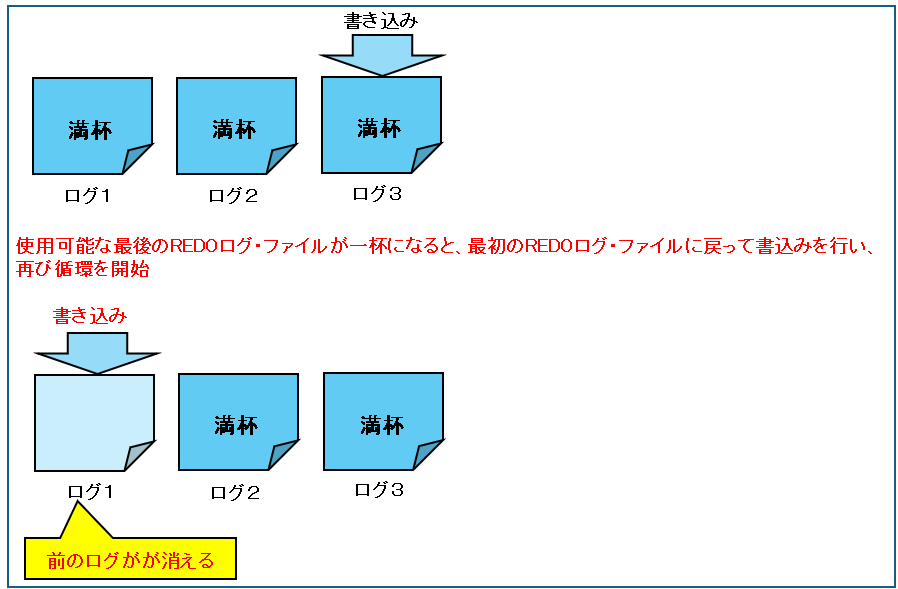
ログが消えてしまうとデータベースに障害が発生した場合、復旧ができなくなるので、満杯になったREDOログをコピーしたアーカイブログファイルとして保管します。
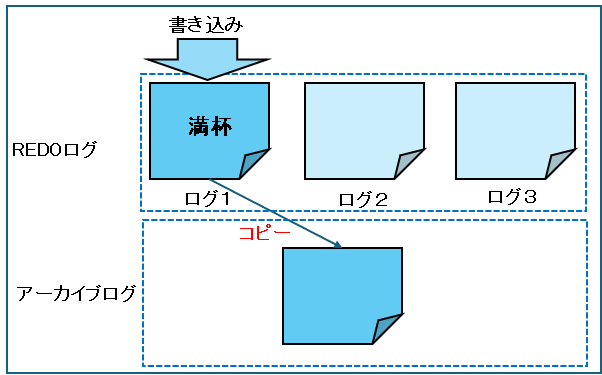
一杯になったグループは、ログスイッチの発生タイミングにどんどんアーカイブとしてコピーされます。
ログの目的はリカバリー
先ほどの章まででREDOログやアーカイブログ出力の説明をしてきましたが、このログを記録する一番の目的は障害発生時のリカバリーです。
ログを使用しない場合の復旧(不完全リカバリー)
通常、データベースは日次でバックアップを取っているのが一般的だと思います。
日次のバックアップだけですと、1日前の状態にもどってしまい、約1日分のデータは失われてしまうので、その日にシステムを使って登録・変更・削除した業務データが失われてしまいます。
例えば、毎日深夜にバックアップを取っているシステムがあったとします。
4月1日にバックアップが無事に取れ、翌日の4月2日に障害が発生してデータが壊れてしまったとします。
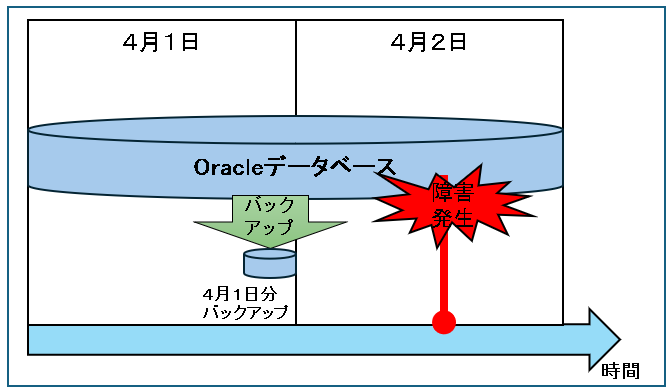
この場合、4月1日の深夜に取得したバックアップで復旧をするので、データは4月1日の深夜時点に戻ってしまい、4月2日の障害直前までに登録更新・変更・削除データは失われてしまいます。
システムにもよりますが、1日分の業務が水の泡というのは大きな損失です。
REDOログやアーカイブログを使用することで、障害発生直前に戻せます。
ログを使ったリカバリ(完全リカバリー)
REDOログ、アーカイブログを使うことで、例えバックアップは日次で取っていたとしても、障害発生直前に復旧をすることが可能になります。
日次バックアップを取っているデータベースの例で説明をします。
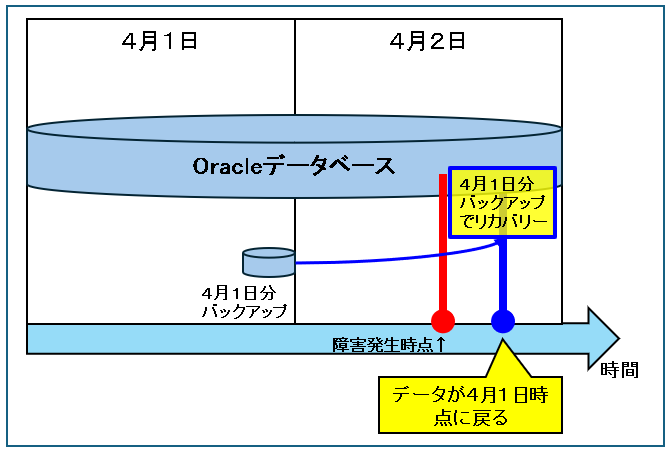
毎日深夜にバックアップを取っているデータベースで、4月2日にシステム障害発生が発生しました。
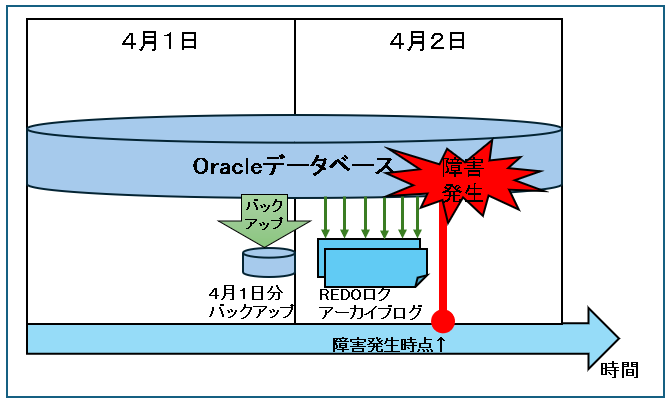
障害発生直前に戻すためには、4月1日のバックアップでリカバリーをしてから、4月1日のREDOログ、アーカイブログを使って復旧直前まで戻します。

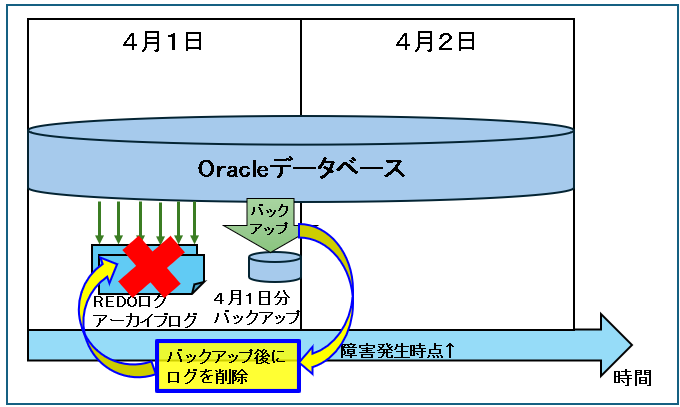
データベースのバックアップ後にログは削除
REDOとアーカイブログは取り続けていると、ファイルのサイズが膨大になり、ディスクの空き領域がなくなってしまう事例が散見されます。
先ほどの章で説明したとおり、データベースの復旧は「バックアップデータ+バックアップ後のログ」を使うので、バックアップ取得後はそれまでのREDOログとアーカイブログは不要になります。
よって、データベースのバックアップを取得後にREDOログとアーカイブログの削除をするのが一般的です。


コメント