
機械学習は大量のデータをコンピュータに覚えさせ、データからからパターン認識や規則を導くことです。
本書は機械学習とは何かの説明からニューラルネットワーク、機械学習の説明をします。
機械学習とは
機械学習は、コンピュータが人間の代わりに「経験から学ぶ」仕組みのことです。
従来のAIを使わない場合、コンピュータは、「もしAならBをしなさい」というルールを、人間がすべて決めます。
しかし、機械学習は「たくさんの例を学習させるから、今後は自分で判断しなさい」ということになります。
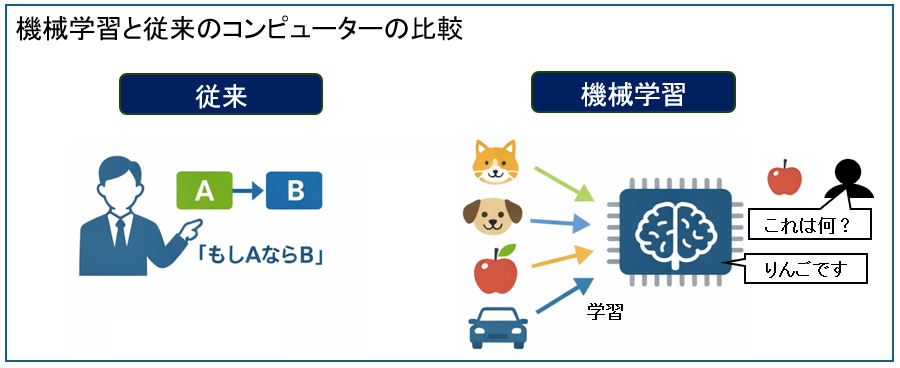
機械学習でできること
- 自然言語処理(NLP)
文章の要約、翻訳、質問応答など - 画像認識
写真に写っているのが「猫」か「犬」かを分類したり、顔を検出して人物を識別したりするなど - 提案
購入履歴からおすすめ商品を表示、視聴履歴から動画を推薦
<機械学習の利用例>
・迷惑メール判定
・YouTubeやNetflixのおすすめ
また、はGoogleが開発した機械学習に特化したTPU(Tensor processing unit)というのもあり、高速かつエネルギー効率がよいことで注目されています。
ニューラルネットワークとは
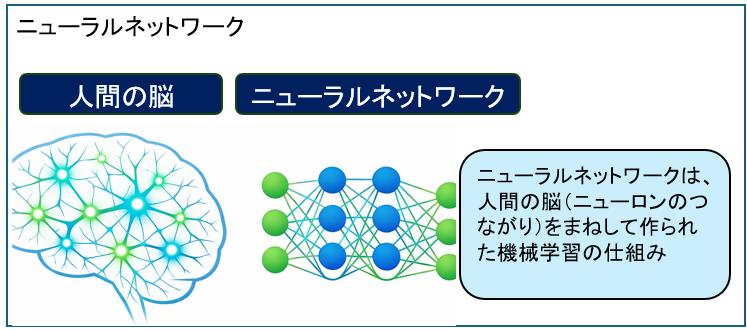
ニューラルネットワークは生物の脳の神経回路を模倣した機械学習モデルの一種で、大量のデータを用いてパターンを学習し、予測や分類などのタスクを実行できる人工知能(AI)の技術です。
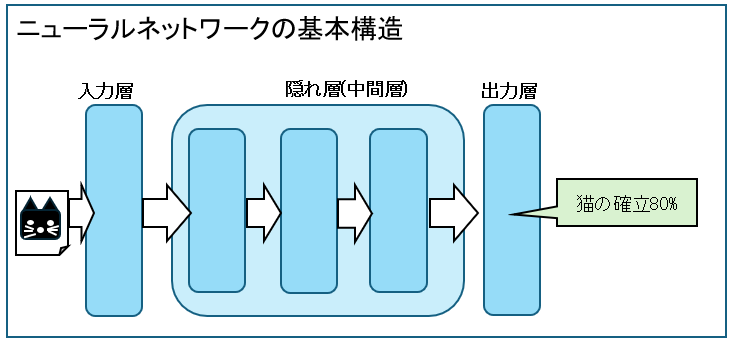
入力層、隠れ層(中間層)、出力層から成っており、入力層はテキストや画像などのデータを受け取り、隠れ層(中間層)では特徴の抽出などが行われ、出力層で結果を返します。
ニューラルネットワークの仕組み:ニューロン、シナプス、バイアスの説明
ニューラルネットワークはたくさんのニューロンで構成されています。
ニューロンは、入力された情報をもとに計算をして、結果を次に渡す小さな計算ユニットです。
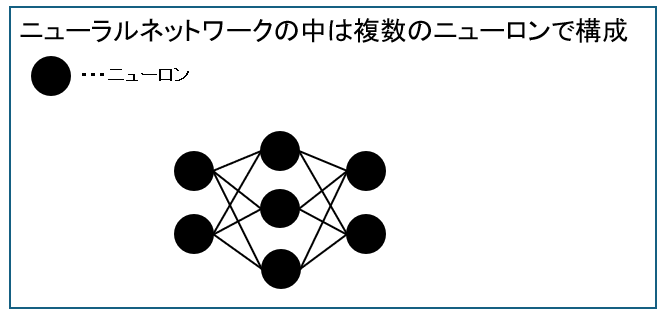
ニューロン同士はシナプスという線でつながっています。
シナプスは情報の通り道であり、接続の強さを意味するので「重み」と言います。
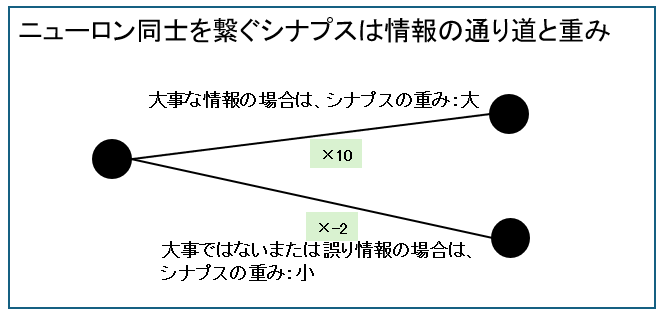
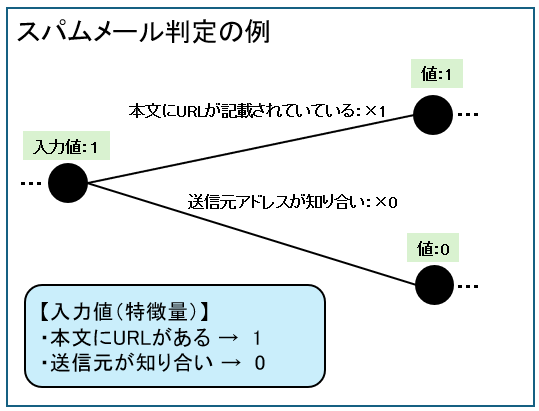
単純なスパムメールの判定例で説明します。
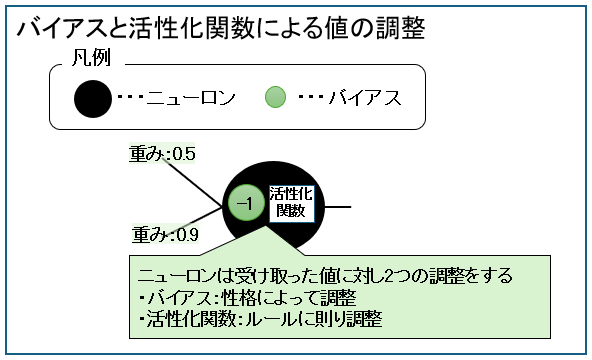
ニューロンは、受け取った値を性格(バイアス)と、ルール(活性化関数)で判断し、値を調整します。
なお、バイアスは入力層には存在しません。
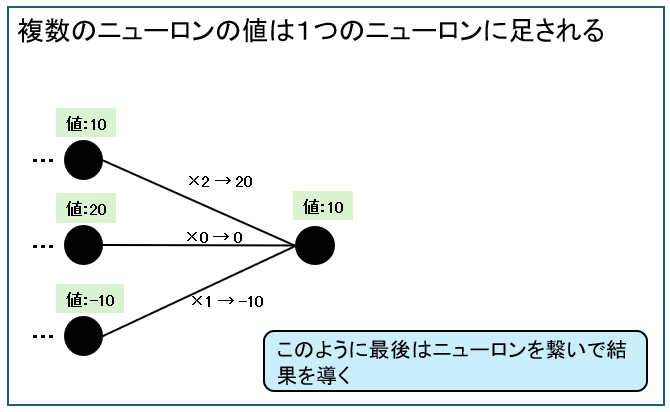
このように前ニューロンからきた値が、次のニューロンにとってどれくらい重要かを計算して結果を導き出します。
今回は単純な例で説明しましたが、層を深くすると、単純な特徴から複雑な特徴へ段階的に変換できます。
これにより、難しい問題や複雑なパターンも学習・理解できます。
「層が深い(ディープ)」ニューラルネットワークは賢くなるということです。
代表的な活性化関数
活性化関数は各ニューロンにおいて、入力された信号をどのように次の層へ出力するかを決定する関数です。
| シグモイド関数 | ・どんな数x を入れても、出力は必ず 0〜1 の間になる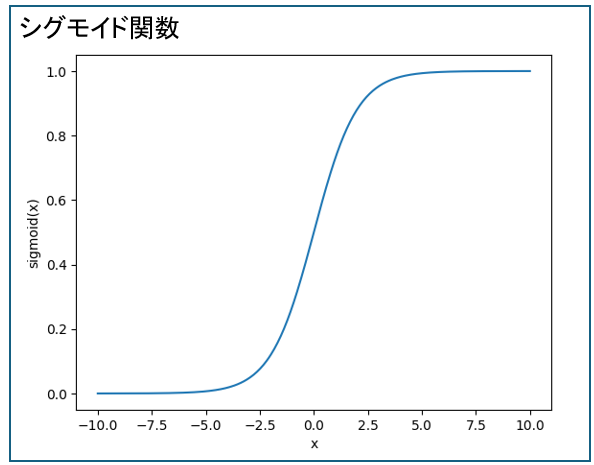 ・例えば「x=0.02の場合:ほぼ違う(y=0)、x=0.95の場合:ほぼ正解(y=1)」のように使う ・ロジスティック回帰などで使う |
| ReLU関数 | ・入力xに対して、xが0以下の場合は0を出力し、x>0 のときはそのままxを出力する。 式:ReLU(x)=max(0,x) 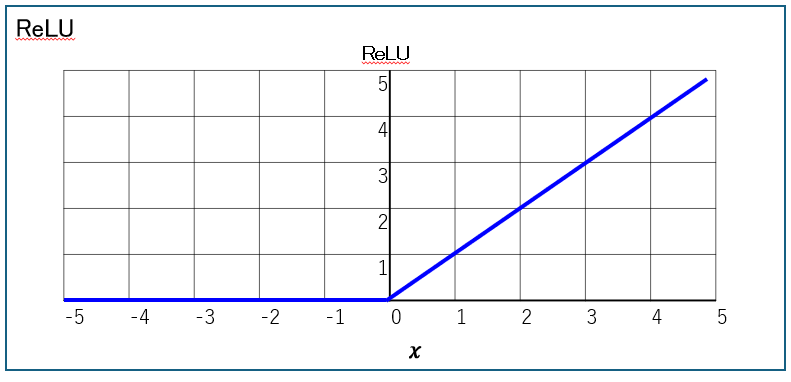 ・意味のない情報などを0にする場合に使用。 ・微分可能で計算も簡便。 ・負の値の場合は無になることが欠点。 |
| Leaky ReLU関数 | ReLUの改良版で、負の入力も「ほんの少しだけ」通す。 |
| GERU関数 | ・ReLUのような急な折れ曲がりではなく、滑らかに値が変化する。 これにより、勾配消失・爆発のリスクを低減し、学習が安定しやすい。 ・ReLUは入力がゼロ以下だと出力が完全にゼロだが、GERUはゼロ付近でも微小な値が出力されるため、ニューロンが「死ぬ」(出力が常にゼロになる)現象が起きにくくなる。 |
| softmax関数 | ・複数の入力値に対し、それぞれの出力値を合計すると1(100%)となるよう正規化する。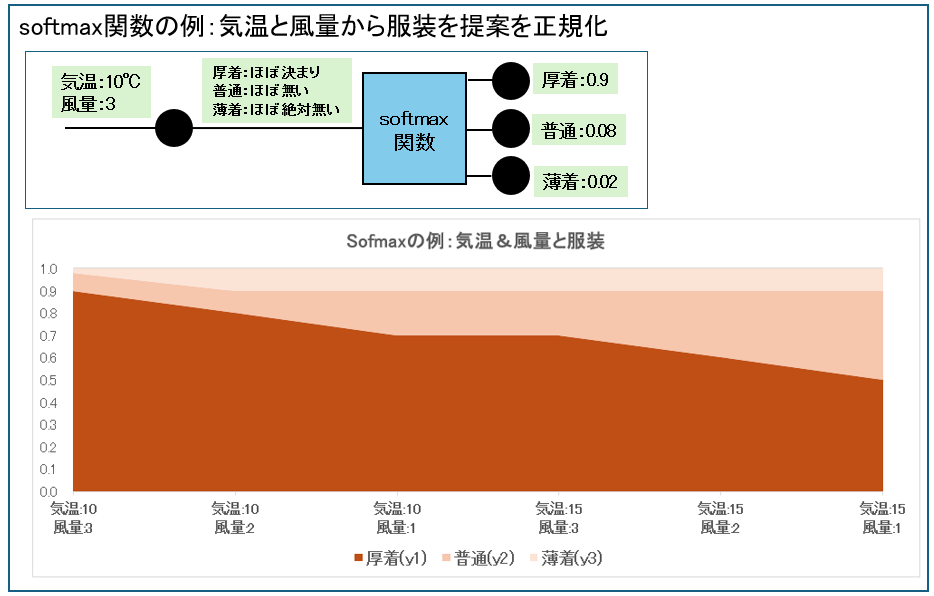 ・シグモイド関数は1か0(例えば「合格」か「不合格」かなど2値だが、sofmax関数は多値となる場合に使用。) |
パラメータ
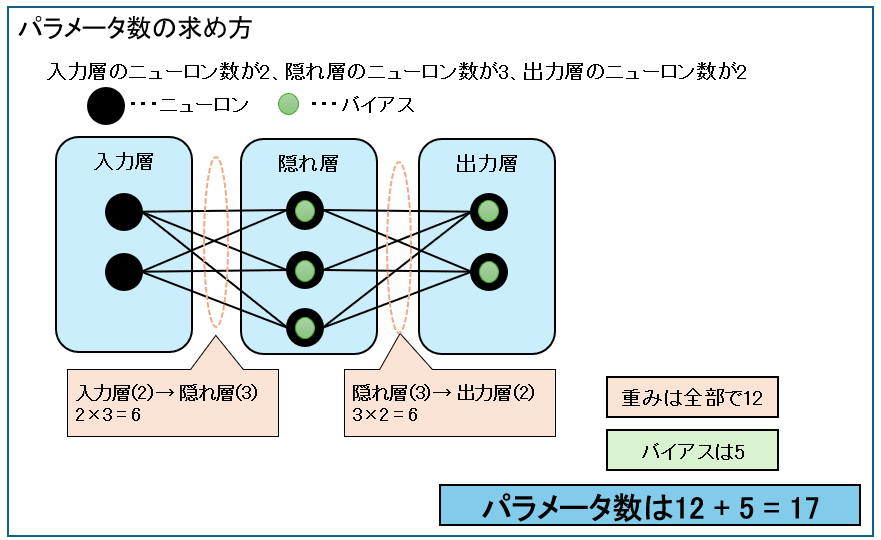
パラメータ数は、ニューラルネットワークにおける重みとバイアスの総数です。
例えば、入力層のニューロン数が2、隠れ層のニューロン数が3、出力層のニューロン数が2の場合のパラメータ数は、以下のようになります。
- 重みの数の計算
入力層のニューロン数(2) × 隠れ層のニューロン数(3) = 6
隠れ層のニューロン数(3) × 出力層のニューロン数(2) = 6 - バイアス数の計算
バイアスは入力層を除く各層のニューロンごとに1つずつ存在しますので
隠れ層(3) + 出力層(2) = 5 - 全パラメータ数の計算
重みの数 + バイアス数 = 6 + 6 + 5 = 17
レイヤー構造
同じ役割・同じ計算を行うニューロン(ユニット)の集合をレイヤーと呼びます。
入力層、隠れ層、出力層もレイヤーです。
ニューラルネットワークの代表的なモデル
ニューラルネットワークで特によく使われているネットワーク アーキテクチャ(構造)について説明します。
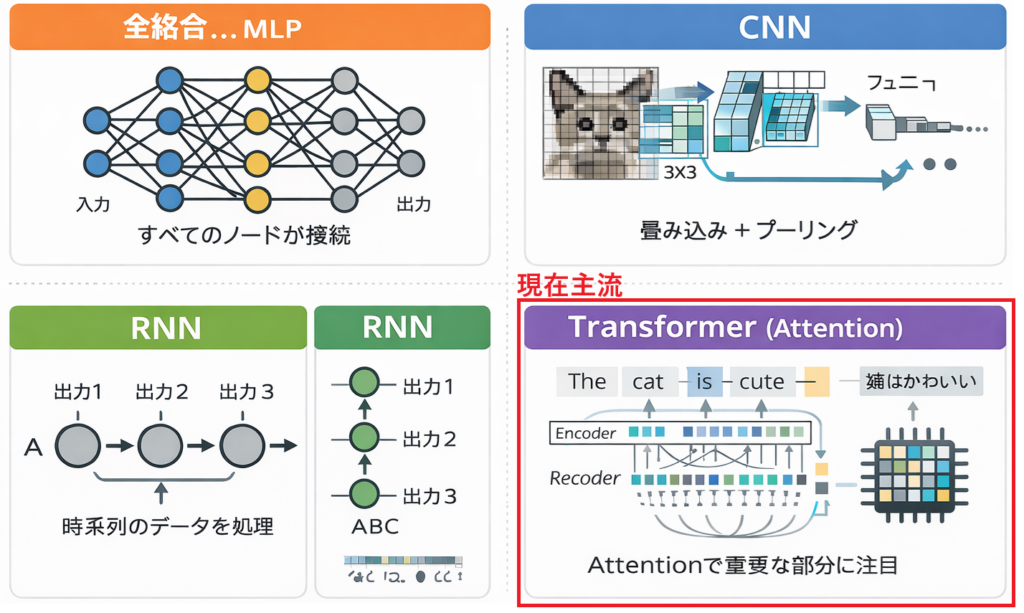
RNN(再帰型ニューラルネットワーク)
RNNは時系列データやシーケンスデータを扱うためのニューラルネットワークです。
過去の情報(隠れ状態)を現在の入力とともに処理することで、文や音声など連続したデータの特徴を学習できます。
下のイメージのように、RNNは現在の入力値と、1時刻前(過去)の隠れ状態を用いて計算をしています。
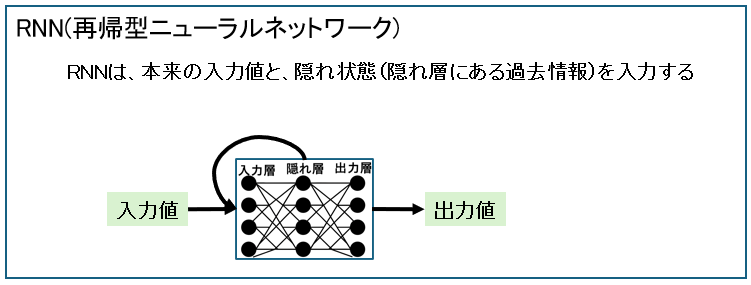
下の例のように文書は、単語(トークン)を1つずつ処理し、隠れ状態(過去情報)が次に渡されるます。これがRNNの「再帰性」です。
しかし、RNNは長文だと精度が落ちるので、トランスフォーマーが主流になっています。
CNN(畳み込みニューラルネットワーク):画像認識
CNNは、画像認識や処理に特化したニューラルネットワークで、顔認証や自動運転で活用されています。
CNNの説明はこちらを参照してください。
LSTM(Long Short Term Memory)
LSTMは、RNNの一種で、長期間にわたる依存関係(長いシーケンスの情報)を保持・学習できるように設計されています。
標準的なRNNの「長期記憶が苦手」という弱点を克服するため、特殊な構造(ゲート機構)を持っています。
トランスフォーマー(Transformer):最近の主流
自己注意機構(Self-Attention)という、ある単語がどの単語に注目すべきか数値化する仕組みにより、従来より精度が向上しています。
トランスフォーマーの説明はこちらを参照してください。
機械学習の3つの学習方法
機械学習は、教師あり学習、教師なし学習、強化学習の3つがあります。
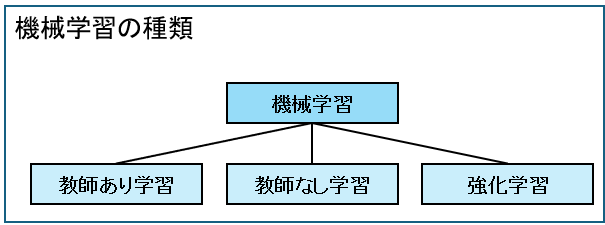
次章からそれぞれの詳細を説明します。
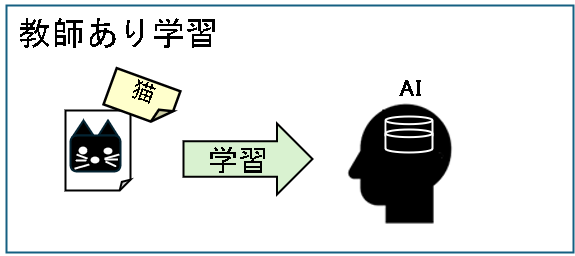
教師あり学習
教師あり学習とは、入力と正解(ラベル)をセットにしたデータを使って、パターンを学習する方法です。
教師なし学習は、学習データにラベルを付けないで学習する方法です。
先ほどの例の続きで説明すると、画像をラベルなしで1週間読み取るうちに、AIが自律的に「猫」というものを認識するようになるということです。
何を出力したいかによって適しているモデルが異なり、出力の種類によって大きく「分類モデル」と「回帰モデル」の2つに分けられます。
分類モデルはカテゴリ(クラス)を出力し、回帰モデルは数値を出力します。
教師あり学習:分類モデル
分類は未知のデータをクラスに分けて学習させる手法です。
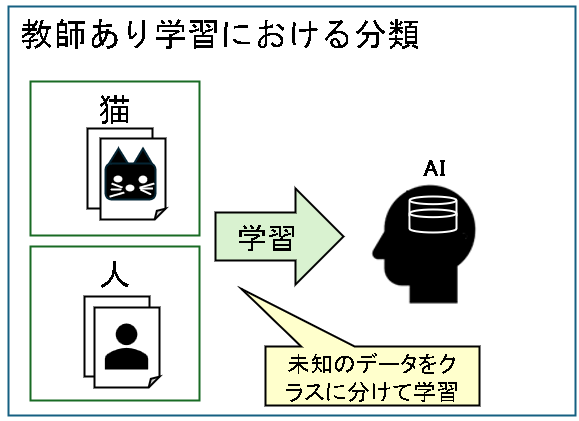
分類は例えば、迷惑メールと正常メールを使って文章の特徴とクラスの関係を学習させ、新着メールがどのクラスに当てはまるのかを予測するときに使えます。
主なアルゴリズムは次の通りです。
| モデル | 説明 |
|---|---|
| ロジスティック回帰 | いくつかの要因(説明変数)から「2値の結果(目的変数を0か1で表現)」に分類する手法。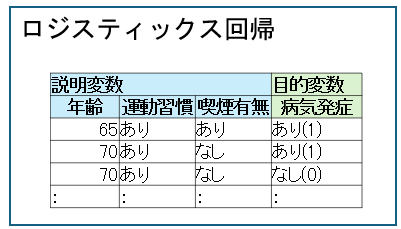 |
| 決定木 | IF・・・THEN・・・形式で学習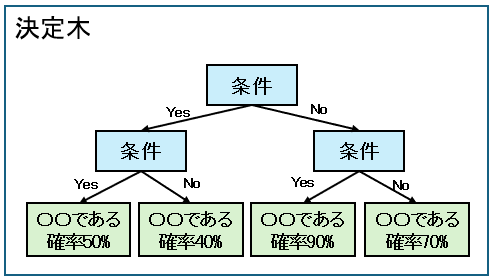 |
| サポートベクターマシン(SVM) | 境界線(決定境界)を引くことでデータを分類する。 少ないデータでも高精度な分類が可能。 例として、スパムメール判定で利用する場合、特徴量として単語の出現頻度などを使用する。 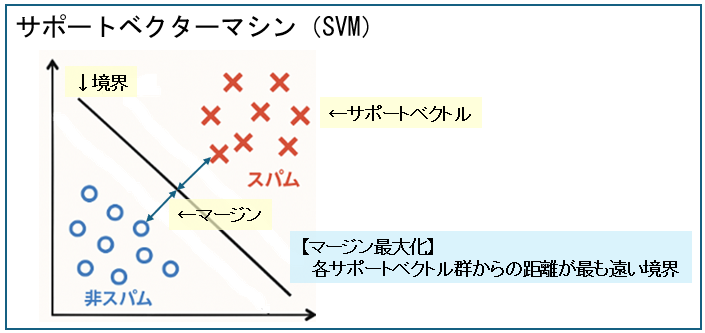 両郡のから遠い位置に境界を「マージン最大化」という。 |
教師あり学習:回帰モデル
回帰はデータの関係性を見つけることができる学習です。
例えば、過去の気象データから翌日の気温を予測したり、商品の広告費や季節などから来月の売上を予測したりできます。
| モデル | 説明 |
|---|---|
| 線形回帰モデル | 目的変数と説明変数の関係性を直線的なモデルで表現したもの。 下のイメージは説明変数:1日の喫煙本数、目的変数:持病数の例です。 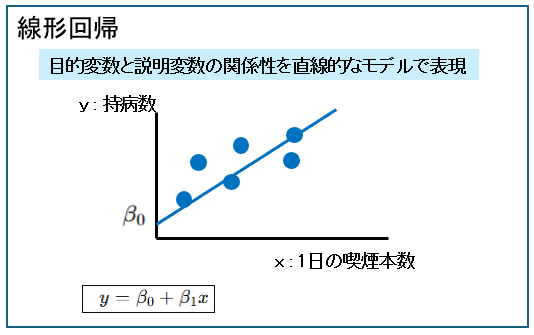 |
| 自己回帰モデル | 過去の自分自身のデータを使って分析。 |
| ベクトル自己回帰モデル(VAR) | 過去の複数の自分自身のデータを使って分析。 |
アンサンブル学習
アンサンブル学習は、分類・回帰の精度を上げるための手法で、複数のモデルを組み合わせて、1つのモデルより良い予測をするします。
一般的に、アンサンブル学習は教師あり学習で使われます。
| 手法 | 説明 |
|---|---|
| バギング | 複数の同じモデルで、各々異なるデータ学習をさせて結果を統合する。 |
| ブースティング | 弱いモデルを複数組み合わせて修正し、より強力なモデルを作成する。 |
| ランダムフォレスト | 複数の決定木を組み合わせて制度を向上させる。 |
教師なし学習
教師なし学習は、ラベル付きデータ(正解データ)がない状態で学習を行う方法です。
つまり、特徴量(データに含まれるパターンや構造)を自動的に見つけ出します。
次の手法があります。
| クラスタリング | データを似ているもの同士でグループ分けする。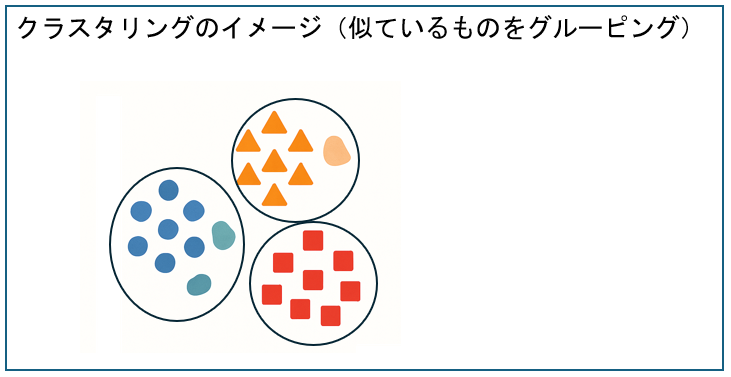 |
| k-means法 | ①クラスタの中心(平均)を k 個、適当に置く ②各データを「一番近い中心」に割り当てる ③各クラスタの中心を平均で更新する ④上の②〜③を繰り返す(収束するまで) |
| アソシエーション分析 | データ内のアイテム間の関連性(ルール)を発見する手法。 例:おむつを買う人は、同時にビールを買う確率が高い |
強化学習
強化学習は、自ら試行錯誤しながら学習していく技術です。
一定の環境の中で試行錯誤を行い、個々の行動に対して得点や報酬を与えることによって、ゴールの達成に向けた行動の仕方を獲得するのです。
なお、CHATGPTは3つを組み合わせ使用してると回答がありました。
・教師あり学習で最初の学習(言語モデルの基盤)を行い、
・教師なし学習でデータからパターンを学び、
・強化学習でユーザーのフィードバックを基にさらに最適化される
という流れです。
学習精度を上げる指標や要素
汎化性能とは
汎化性能は未知データに対する予測精度で、将来のデータに対してどれだけ正確に予測できるかを表します。
学習データだけにピッタリ合っている状態は汎化性能が低い状態といえます。
これの原因は過学習です。(この後の章で解説)
損失関数とは
損失関数は、モデルの予測がどれくらい間違っているかを数値で表すものです。
つまり、予測と実際の値のズレの大きさを表す関数です。
主に教師あり学習では予測と正解のズレを測る必要があるので損失関数が使用されます。
| 損失関数 | 説明 |
|---|---|
| 平均二乗誤差(MSE) | ・主に回帰問題で使われます。 ・誤差を二乗してから平均を計算して求めます。 ・例えば線形モデルy-2x+1でxと実際の値が次の表の平均二乗誤差を考えます。 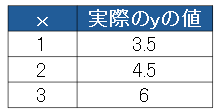 各々予測yを求め、誤差を求めて2乗した値の平均が平均二乗法誤差である  |
| 平均絶対誤差(MAE) | ・予測と実際の差の絶対値の平均で求めます。 ・外れ値(異常に大きな誤差)に対してMSEよりも頑健(影響を受けにくい)です。 ・例えば線形モデルy-2x+1でxと実際の値が次の表の平均絶対誤差を考えます。 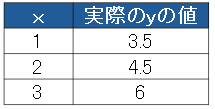 予測yを求め、誤差(実測値 − 予測値)の絶対値の平均が平均絶対誤差である  |
■多クラス分類
| 損失関数 | 説明 |
|---|---|
| 交差エントロピー | ・正解ラベルと予測確率のズレの確率を出します。 正解ラベルと予測確率のズレが低ければ交差エントロピーは小さくなります。 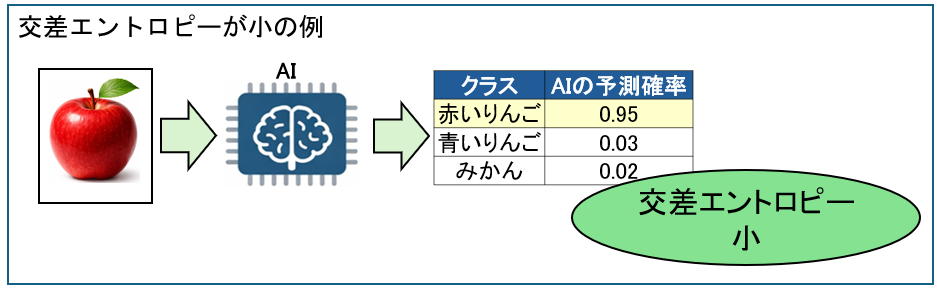 正解ラベルと予測確率のズレが高ければ交差エントロピーは大きくなります。 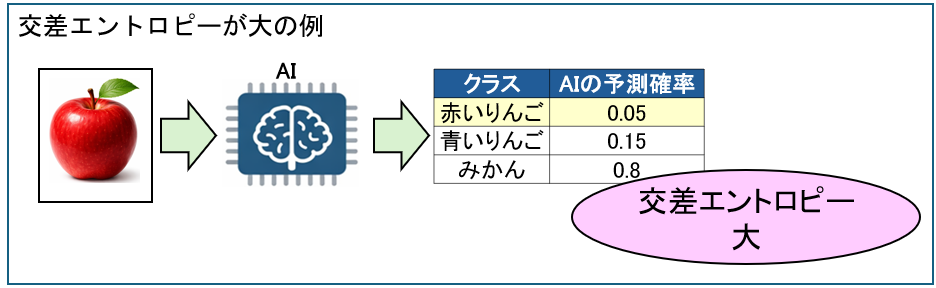 |
過学習を防止
過学習は、訓練データに“合わせすぎて”しまい、新しいデータに対してうまく予測できなくなる状態のことです。
■過学習の原因
- モデルが複雑すぎる(パラメータが多い) ※大きなモデルは良い
※シンプルなモデルは「覚えすぎ」を防ぎやすい - データが少ない
- ノイズ(偶然のパターン)まで覚えてしまう
■過学習を防ぐ方法
| 手法 | 説明 |
|---|---|
| ドロップアウト | 毎回ランダムに一部のノード(ニューロン)を無効化する。 |
| データを増やす | 可能ならデータ収集、難しければデータ拡張を使用 |
| モデルをシンプルにする | パラメータ数を減らす 深すぎるネットワークを避ける |
| 学習の早期終了 | データの性能が悪化し始めたら学習を止める |
学習を効率よくするための手法
ここから説明するのは学習の3種類と組み合わせて使われる考え方です。
移転学習
すでに学習済みのモデルの知識を、別の似た問題に再利用する方法です。
少ないデータでも高い性能を出しやすくなります。
■移転学習の代表的な手法
| 手法 | 説明 |
|---|---|
| ファインチューニング | 既存の学習済みモデルのパラメータを、新しいタスク用に微調整する方法。 (例:画像認識の大規模モデルを、別の特定の画像分類に適用する) |
| 蒸留 | 大きな教師モデルの知識を、小さな生徒モデルに移す技術 |
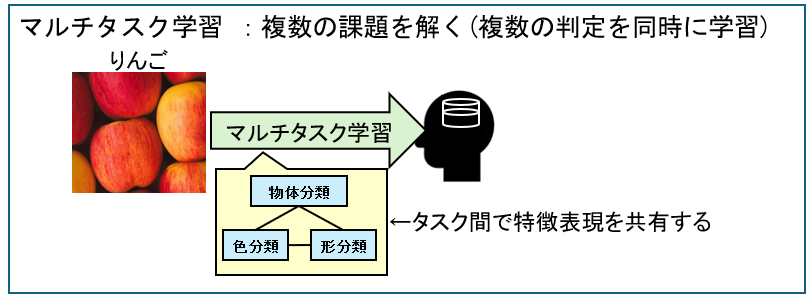
マルチタスク学習
1つのモデルで、複数の関連する問題を同時に学習する方法です。
まとめて学ぶことで、精度の向上が期待できます。
例えば、単一タスク学習では、「りんご」か「りんご以外」かを判定する1つの問題だけを学習します。
一方、マルチタスク学習では、「りんごかどうか」に加えて、「りんごの色(赤・青)」や「形の種類」など、複数の判定を同時に学習します。
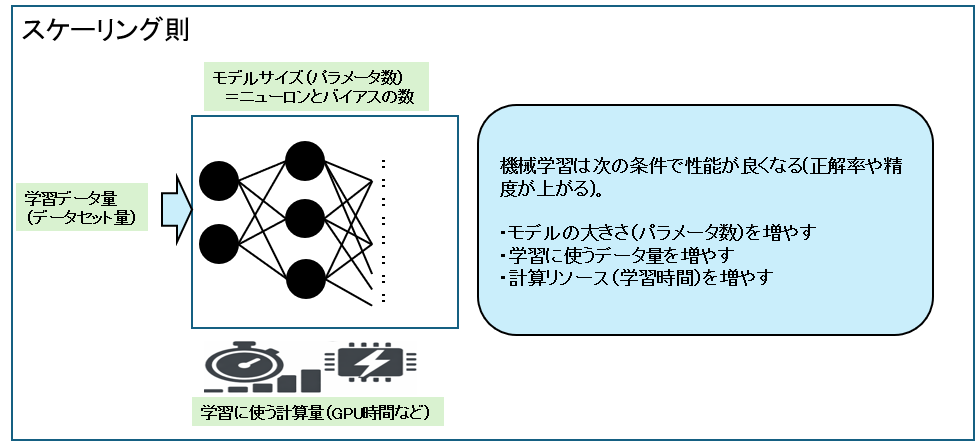
スケーリング則
機械学習は次の条件で性能が良くなります。(正解率や精度が上がる)。これをスケーリング則といいます。
・モデルの大きさ(パラメータ数)を増やす
・学習に使うデータ量を増やす
・計算リソース(学習時間)を増やす
機械学習に向いているプロセッサ
通常のパソコンの脳みそに該当するプロセッサはCPUですが、AI(特にディープラーニング)の処理においてはGPU(Graphics Processing Unit)の方が適しています。
CPUは少ないコアで少数の処理を順番に処理するのが特徴ですが、GPUは数千個の小さなコアを搭載しているので同時に大量の計算を並列で処理できます。
AIの分野においては並列計算が得意なGPUが圧倒的に有利なのです。
まとめ
- AI(特にディープラーニング)の処理においてはGPU(Graphics Processing Unit)が適している
- ニューラルネットワークは生物の脳の神経回路を模倣した機械学習モデル
- ニューラルネットワークはたくさんのニューロンで構成されシナプスという線でつながっている
- ニューロンは、受け取った値を性格(バイアス)とルール(活性化関数)で判断して値を調整
- ニューラルネットワークの構造は、RNN(時系列データやシーケンスデータを扱う)、CNN(画像認識)、LSTM(RNNの一種で長期間の依存関係を学習)、トランスフォーマー(自己注意機構)がある。
- 機械学習は教師あり学習、教師なし学習、強化学習がある。


コメント